Service Discovery
Context
微服务就是将之前的单体服务按照业务维度进行拆分,拆分粒度可大可小,拆分时机可以分节奏进行。最佳实践是先将一些独立的功能从单体中剥离出来抽成一个或多个微服务,这样可以保障业务的连续性和稳定性。
服务通常需要相互呼叫。在整体式应用程序中,服务通过语言级方法或过程调用相互调用。在传统的分布式系统部署中,服务在固定的、已知的位置(主机和端口)运行,因此可以使用 HTTP/REST 或某些 RPC 机制轻松相互调用。
服务的地址写死在数据库或者配置文件,通过访问DNS域名进行寻址路由。
服务B的地址硬编码在数据库或者配置文件中,服务A首先需要拿到服务B的地址,然后通过DNS服务器解析获取其中一实例的真实地址,最后可以向服务B发起请求。
在物理硬件上运行的传统应用程序中,服务实例的网络位置是相对静态的。
但是,基于微服务的现代应用程序通常在虚拟化或容器化环境中运行,其中服务的实例数量及其位置会动态变化。
服务的客户端(API 网关或其他服务)如何发现服务实例的位置?
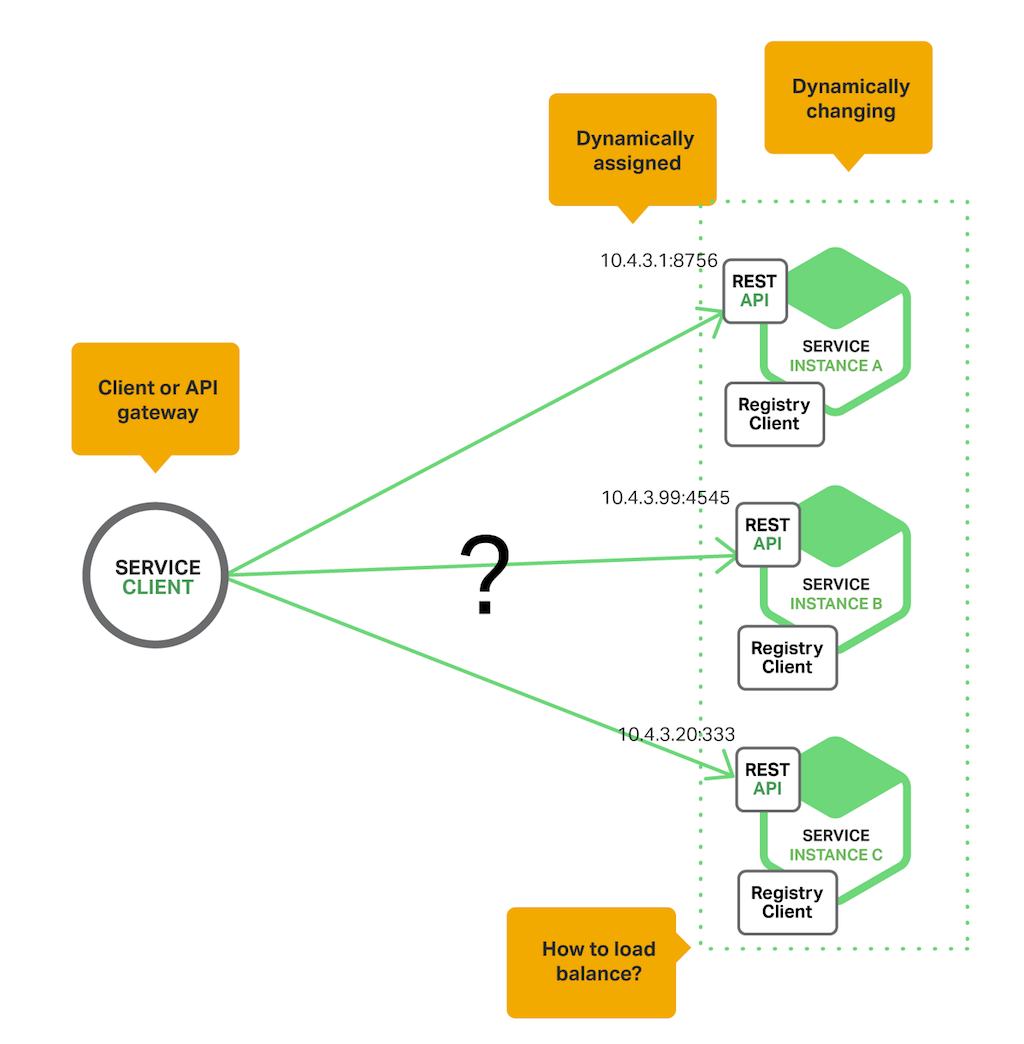
服务实例具有动态分配的网络位置。此外,由于自动缩放、故障和升级,服务实例集会动态更改。因此,客户端代码需要使用更复杂的服务发现机制。
有两种主要的服务发现模式:客户端发现和服务器端发现。让我们先看一下客户端发现
Solution
The Client‑Side Discovery Pattern
使用客户端发现时,客户端负责确定可用服务实例的网络位置,并在这些实例之间对请求进行负载均衡。客户端查询服务注册表,该注册表是可用服务实例的数据库。然后,客户端使用负载平衡算法选择一个可用的服务实例并发出请求。
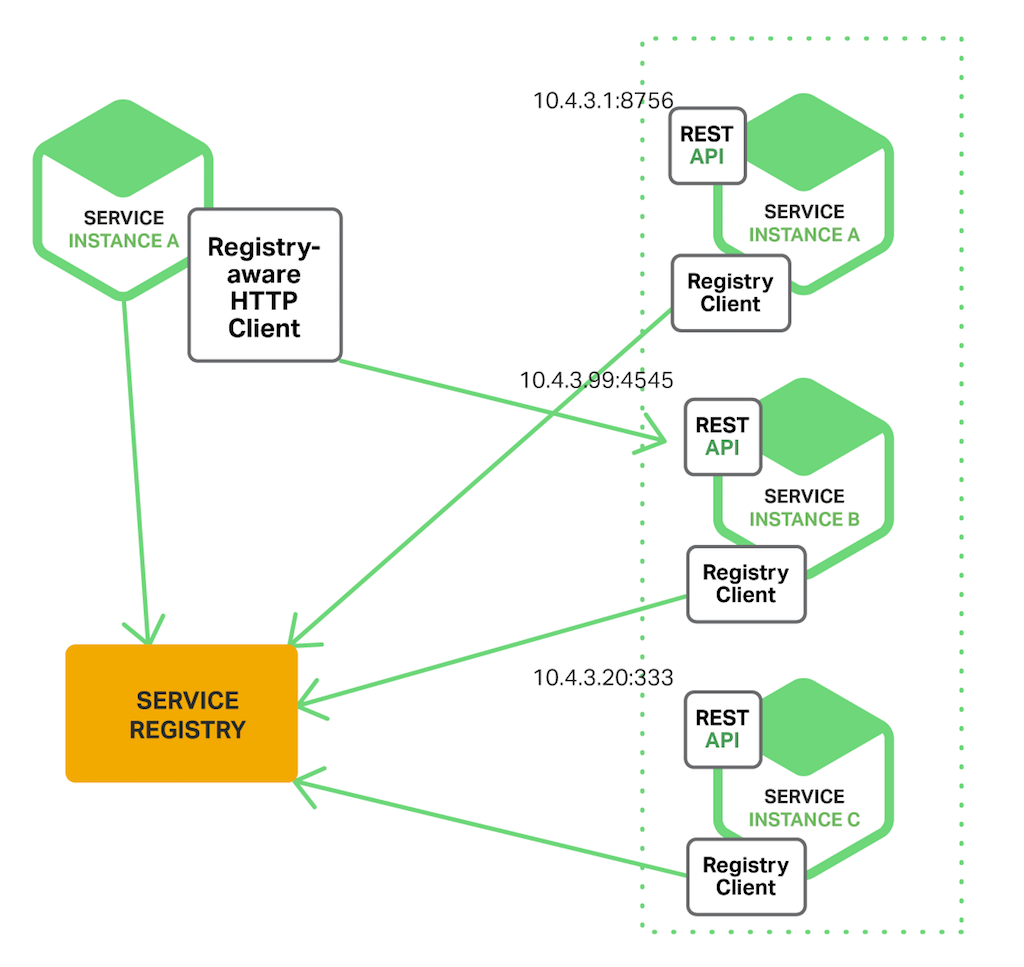
服务实例的网络位置在启动时注册到服务注册表。当实例终止时,它将从服务注册表中删除。通常使用检测信号机制定期刷新服务实例的注册。
这种模式相对简单,除了服务注册表之外,没有其他移动部件。此外,由于客户端知道可用的服务实例,因此它可以做出智能的、特定于应用程序的负载平衡决策,例如一致性哈希。此模式的一个显著缺点是它将客户端与服务注册表耦合在一起。必须为服务客户端使用的每种编程语言和框架实现客户端服务发现逻辑。
客户端发现模式的优缺点如下:
优点:
负载均衡作为client中一个功能,用自身的算法,从服务提供者列表中选择一个合适服务提供者进行访问,因此client端可以定制化负载均衡算法。优点是服务客户端可以灵活、智能地制定负载均衡策略,包括轮询、加权轮询、一致性哈希等策略。
可以实现点对点的网状通讯,即去中心化的通讯。可以有效避开单点造成的性能瓶颈和可靠性下降等问题。
服务客户端通常以SDK的方式直接引入到项目,这种方式语言的整合程度最佳,程序执行性能最佳,程序错误排查更加容易。
缺点:
当负载均衡算法需要更新时候,很难做到同一时间全部更新,所以就造成新旧算法同时运行
与注册中心紧密耦合,如果要换注册中心,需要去修改代码,重新上线。微服务的规模越大,服务更新越困难,这在一定程度上违背了微服务架构提倡的技术独立性。
The Server‑Side Discovery Pattern
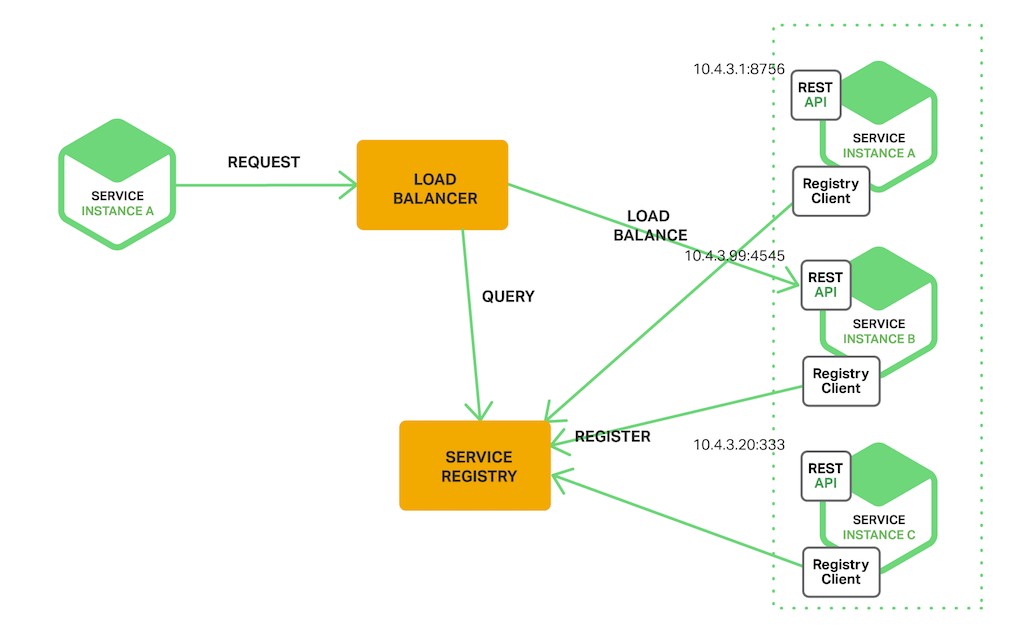
客户端通过负载均衡器向服务发出请求。负载均衡器查询服务注册表,并将每个请求路由到可用的服务实例。与客户端发现一样,服务实例在服务注册表中注册和注销。
某些部署环境(如 Kubernetes 和 Marathon)在群集中的每个主机上运行代理。代理扮演服务器端发现负载均衡器的角色。为了向服务发出请求,客户端使用主机的 IP 地址和服务分配的端口通过代理路由请求。然后,代理以透明方式将请求转发到集群中某个位置运行的可用服务实例。
服务器端发现模式有几个优点和缺点。这种模式的一大好处是,发现的细节是从客户端中抽象出来的。客户端只需向负载均衡器发出请求即可。这样就无需为服务客户端使用的每种编程语言和框架实现发现逻辑。此外,如上所述,某些部署环境免费提供此功能。然而,这种模式也有一些缺点。除非负载平衡器由部署环境提供,否则它是需要设置和管理的另一个高可用性系统组件。
服务端发现模式的特点如下:
优点:
服务消费者不需要关心服务提供者的列表,以及其采取何种负载均衡策略
负载均衡策略的改变,只需要注册中心修改就行,不会出现新老算法同时存在的现象
服务提供者上下线,对于服务消费者来说无感知
缺点:
rt增加,因为每次请求都要请求注册中心,尤其返回一个服务提供者
注册中心成为瓶颈,所有的请求都要经过注册中心,如果注册服务过多,服务消费者流量过大,可能会导致注册中心不可用
微服务的一个目标是故障隔离,将整个系统切割为多个服务共同运行,如果某服务无法正常运行,只会影响到整个系统的相关部分功能,其它功能能够正常运行,即去中心化。然而,服务端发现模式实际上是集中式的做法,如果路由器或者负载均衡器无法提供服务,那么将导致整个系统瘫痪。
The Service Registry
服务注册表是服务发现的关键部分。它是一个包含服务实例的网络位置的数据库。服务注册表需要具有高可用性和最新状态。客户机可以缓存从服务注册表获取的网络位置。但是,该信息最终会过时,客户端将无法发现服务实例。因此,服务注册表由一个服务器集群组成,这些服务器集群使用复制协议来保持一致性。
服务注册表的其他示例包括:
etcd – 一个高度可用、分布式、一致的键值存储,用于共享配置和服务发现。两个使用 etcd 的著名项目是 Kubernetes 和 Cloud Foundry。
consul – 用于发现和配置服务的工具。它提供了一个 API,允许客户端注册和发现服务。Consul 可以执行健康检查以确定服务的可用性。
Apache Zookeeper – 一种广泛使用的高性能分布式应用程序协调服务。Apache Zookeeper 最初是 Hadoop 的一个子项目,但现在是一个顶级项目。
此外,如前所述,某些系统(如 Kubernetes、Marathon 和 AWS)没有明确的服务注册表。相反,服务注册表只是基础结构的内置部分。
服务注册有两种形式:客户端注册和代理注册。
客户端注册
客户端注册是服务自己要负责注册与注销的工作。当服务启动后注册线程向注册中心注册,当服务下线时注销自己。
这种方式的缺点是注册注销逻辑与服务的业务逻辑耦合在一起,如果服务使用不同语言开发,那需要适配多套服务注册逻辑。
代理注册
代理注册由一个单独的代理服务负责注册与注销。当服务提供者启动后以某种方式通知代理服务,然后代理服务负责向注册中心发起注册工作。
这种方式的缺点是多引用了一个代理服务,并且代理服务要保持高可用状态。
Service Registration Options
如前所述,服务实例必须在服务注册表中注册和注销。有几种不同的方法可以处理注册和注销。一种选择是让服务实例自行注册,即自注册模式。另一个选项是让其他一些系统组件来管理服务实例的注册,即第三方注册模式。先来看一下自注册模式。
The Self‑Registration Pattern
使用自注册模式时,服务实例负责向服务注册表注册和取消注册自身。此外,如果需要,服务实例会发送检测信号请求以防止其注册过期。下图显示了此模式的结构。
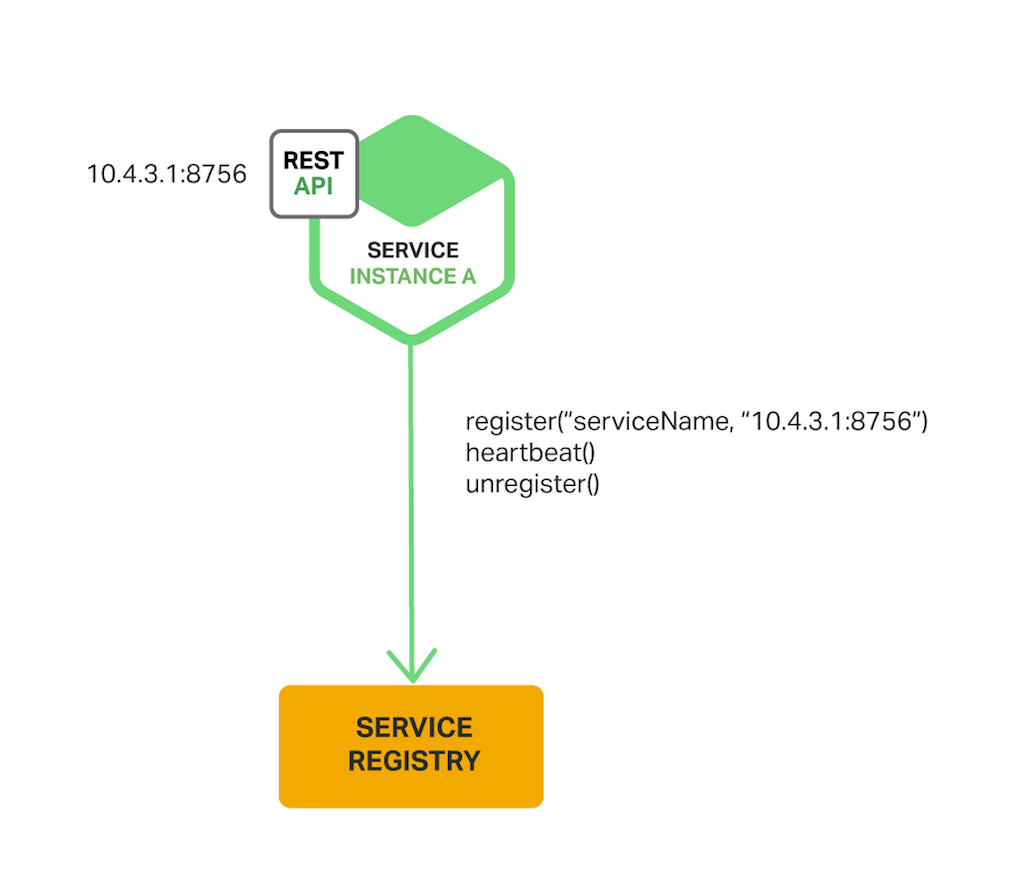
Spring Cloud 项目实现了包括服务发现在内的各种模式,可以轻松地自动向 Eureka 注册服务实例。您只需使用注释来 @EnableEurekaClient 注释 Java Configuration 类即可。
自助注册模式有各种优点和缺点。一个好处是它相对简单,不需要任何其他系统组件。但是,一个主要缺点是它将服务实例耦合到服务注册表。您必须在服务使用的每种编程语言和框架中实现注册代码。
The Third‑Party Registration Pattern
使用第三方注册模式时,服务实例不负责向服务注册表注册自己。相反,另一个称为服务注册器的系统组件将处理注册。服务注册器通过轮询部署环境或订阅事件来跟踪对正在运行的实例集的更改。当它注意到一个新可用的服务实例时,它会将该实例注册到服务注册表。服务注册器还会取消注册已终止的服务实例。下图显示了此模式的结构。
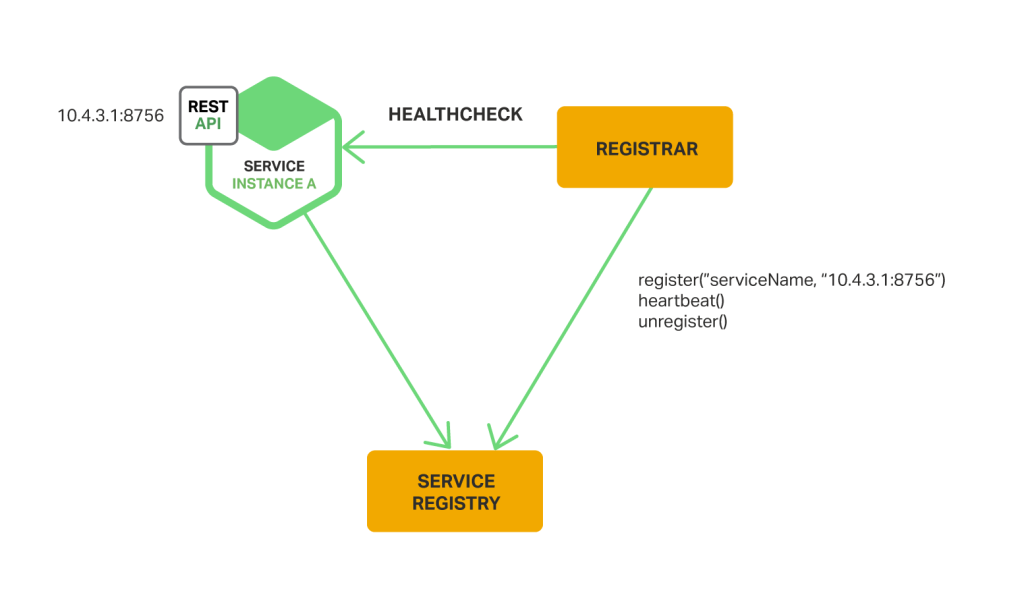
服务注册商的一个示例是开源注册商项目。它会自动注册和取消注册部署为 Docker 容器的服务实例。Registrator 支持多个服务注册机构,包括 etcd 和 Consul。
服务注册器是部署环境的内置组件。Autoscaling Group 创建的 EC2 实例可以自动注册到 ELB。Kubernetes 服务会自动注册并可供发现。
优缺点
一个主要的好处是服务与服务注册表分离。无需为开发人员使用的每种编程语言和框架实现服务注册逻辑。相反,服务实例注册在专用服务中以集中方式处理。
此模式的一个缺点是,除非它内置到部署环境中,否则它是另一个需要设置和管理的高可用性系统组件。
etcd
Etcd是基于Go语言实现的一个KV结构的存储系统,支持服务注册与发现的功能,官方将其定义为一个可信赖的分布式键值存储服务,主要用于共享配置和服务发现。其特点如下:
- 安装配置简单,而且提供了 HTTP API 进行交互,使用也很简单 键值对存储:
- 据存储在分层组织的目录中,如同在标准文件系统中
- 变更:监测特定的键或目录以进行更改,并对值的更改做出反应
- 根据官方提供的 benchmark 数据,单实例支持每秒 2k+ 读操作
- 采用 Raft 算法,实现分布式系统数据的可用性和一致性
服务注册
每一个服务器启动之后,会向Etcd发起注册请求,同时将自己的基本信息发送给 etcd 服务器。服务器的信息是通过KV键值进行存储。key 是用户真实的 key, value 是对应所有的版本信息。keyIndex 保存 key 的所有版本信息,每删除一次都会生成一个 generation,每个 generation 保存了这个生命周期内从创建到删除中间的所有版本号。
更新数据时,会开启写事务。
- 会根据当前版本的key,rev在 keyindex 中查找是否有当前 key 版本的记录。主要获取 created 与 ver 的信息。
- 生成新的 KeyValue 信息。
- 更新 keyindex 记录。
健康检查
在注册时,会初始化一个心跳周期 ttl 与租约周期 lease。服务器需要在心跳周期之内向 etcd 发送数据包,表示自己能够正常工作。如果在规定的心跳周期内,etcd 没有收到心跳包,则表示该服务器异常,etcd 会将该服务器对应的信息进行删除。如果心跳包正常,但是服务器的租约周期结束,则需要重新申请新的租约,如果不申请,则 etcd 会删除对应租约的所有信息。
在 etcd 中,并不是在磁盘中删除对应的 keyValue 信息,而是对其进行标记删除。
- 首先在 delete 中会生成一个 ibytes,对其追加标记,表示这个 revision 是 delete。
- 生成一个 KeyValue,该 KeyValue 只包含Key的信息。
- 同时修改 Tombstone 标志位,结束当前生命周期,生成一个新的 generation,更新 kvindex。
❝ 再次需要做个说明,因为笔者是从事c++开发的,现在线上业务用的zookeeper来作为注册中心实现服务发现功能。上半年的时候,也曾想转到etcd上,但是etcd对c++并不友好,笔者用了将近两周时间各种调研,编译,发现竟然不能将其编译成为一个静态库…
需要特别说明的是,用的是etcd官网推荐的 c++客户端etcd-cpp-apiv3) ❞
reference
Service Discovery in Microservices | Baeldung on Computer Science