Consistency between Cache and Database
在如今的系统开发中,为了提高业务和接口的处理速度,缓存数据已经变成开发模式的常规操作。通过引入缓存减少数据库的查询操作,提高数据的查询速度。但任何一件事情都要从它的两个面去看。引入缓存在带来诸多优势的同时,也相应的提高了系统的复杂性,比如:如何保证缓存和数据库的一致性。
缓存策略
在实际业务中,我们经常采用的一种缓存策略如下:
缓存-数据库读流程
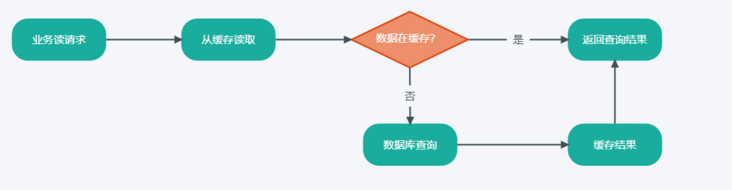
用户发起查询请求
业务服务首先根据关键参数作为key查询缓存
如果数据在缓存中存在cache hit,则直接返回缓存中查询结果。
如果数据不在缓存中cache miss,则进行数据库查询操作,将结果缓存并返回查询结果。
缓存-数据库写流程
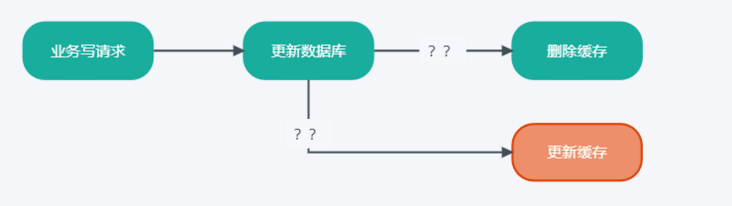
- 用户发起请求,需要写数据。
- 业务服务在完成逻辑处理后,开始更新数据库。
- 数据库更新完成后根据key删除缓存数据(or 更新?)
上述这种数据缓存策略被称为旁路缓存策略(Cache-Aside Strategy),其核心思想是:只有当有应用来请求时,才将对应的对象进行缓存。并且这种策略适用于读取频繁但是写入或更新不频繁的场景,即数据一旦写入后主要用于查询展示,基本不会更新。
另外常用的还有其他两种策略:
- 读写穿透缓存策略(Read-Through/Write-Through Caching Strategy):读写请求由缓存层统一封装处理,业务服务仅操作缓存。
- 异步写入缓存策略(Write-Behind Caching Strategy):数据读取与Read-Through类似,但是数据写入由独立线程异步批量处理更新数据库。
以上为常用的三种缓存策略,后期再做详细说明,本文仅针对Cache-Aside进行分析说明。
问题引入
在Cache-Aside策略下,当出现数据写入/更新请求处理中有这样两个问题需要选择:
- 问题一:对缓存中的老数据进行更新还是删除?
- 问题二:在处理时先更新数据库还是先处理缓存
更新 OR 删除
假设我们选择的是缓存更新,下面来分析在实际多请求并发的情况下
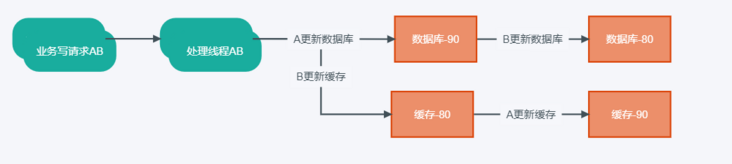
- 同时有请求A和B对数据进行更新操作;
- 在各自的业务线程A和B中对请求进行处理;
- 线程A更新数据库为90,线程B更新数据库为80;
- 因线程A、B并发执行,B优先更新了缓存,随后线程A执行缓存更新,导致数据库中值为80,缓存中数据为90,出现数据库和缓存的不一致。
基于这个场景来看,确实选择删除缓存可以避免出现类似问题,最多会出现cache miss,触发从数据库查询加载。但是,删除缓存就是完美的吗?
先数据库 OR 先缓存
在标准的做法里,我们选择的是先完成数据库的更新操作,然后操作缓存。首先业务操作的结果只有在数据库完成持久化,才算是完成的标志,其次我们来看下先淘汰缓存可能出现的问题。
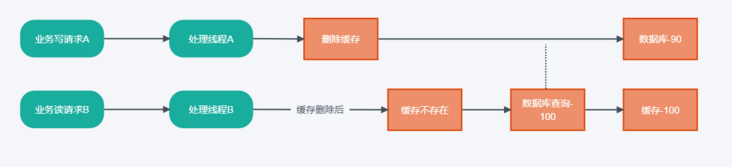
- 同时有请求A进行数据更新和请求B进行查询;
- 线程A先完成缓存删除操作;
- 因为并发的存在,线程B在A删除缓存后执行,因cache miss触发数据库查询加载
- 线程B完成数据库查询,得到旧的数据100,并缓存查询结果。
- 线程A完成数据库更新,数据库中结果为90,导致出现缓存和数据库的不一致。
那如果选择先更新数据库,一定能保证一致性吗?不一定。
- 场景一:缓存删除失败。
在完成数据库的操作后,因为缓存服务等原因导致缓存删除失败,导致数据库和缓存出现不一致。
- 场景二:缓存失效
通常我们缓存的数据都会设置一定的有效期,那么还是回到多请求并发的情况下
- 同时有请求A进行数据更新和请求B进行查询;
- 线程A进行数据库更新操作;
- 线程B查询请求时缓存数据已过期,触发数据库查询加载(这里等同于先执行了删除)。线程B完成数据库查询拿到老数据100;
- 线程A完成数据库更新为90,然后删除缓存
- 线程B执行缓存操作,设置缓存数据为100。缓存和数据库出现了不一致。
但是这些情况出现需要几个前提:
一是缓存平台出现异常,概率较低;
二是缓存数据过期,并且是数据库查询操作比更新操作耗时更久,导致后设置缓存,概率可以说是极小。
能保持一致吗?
通过上面几种场景的分析,会发现即使我们选择标准的旁路缓存的策略,依然没办法保证100%的数据一致。到这里,就需要引入分布式系统下核心的CAP理论。基于CAP理论分析,使用缓存的系统属于CAP理论中的AP,所以我们无法保证强一致性,而只能实现BASE理论中最终的一致,即保证缓存和数据库这个数据最终一致。
最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
最终一致方案
延时双删方案
从名字可以看出方案的本质在于在延迟一定时间后,再进行一次缓存的删除,来解决并发情况下缓存到老数据的问题,即使先操作缓存后操作数据库也可以保证最终数据的一致。
方案流程

用户发起请求,需要写入更新数据
业务服务首先进行删除缓存
然后业务服务进行数据库的更新操作
在延迟一定时间T后,再执行一次缓存删除。
方案分析
该方案的核心点在于延迟时间T,通常我们把T设置为相同业务中一次查询操作耗时+几百毫秒,这样保证了第二次的删除可以清除掉因并发导致的缓存脏数据。
该方案的劣势在于:
- 需要针对也许评估延迟时间,并增加二次删除逻辑,代码强耦合,增加了复杂度。
- 二次删除也可能出现缓存失败。
缓存删除重试
为了保证缓存删除成功,需要在缓存失败时增加重试机制。可以借助消息队列,将删除失败的数据进行异步重试。
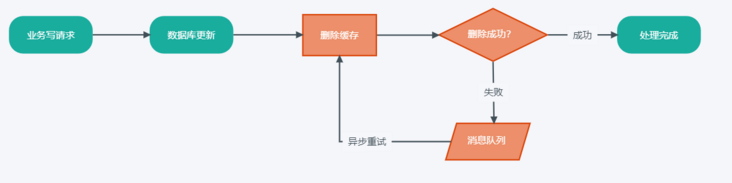
- 用户发起请求,需要写入更新数据
- 业务服务首先进行数据库更新操作
- 然后业务服务进行缓存删除,因某些原因导致失败
- 将删除失败缓存key进入消息队列
- 消费消息队列中的消息,获取需要重试的缓存key
- 重试缓存删除操作
方案分析
该方案虽然将重试逻辑拆除独立执行,但需要在正常业务逻辑中加入删除失败处理代码,侵入性很强。
BinLog缓存删除方案
数据库的BinLog存储了对数据库的更改操作日志记录,通过订阅该日志,来进行缓存的更新,业务代码不再关心缓存更新操作。
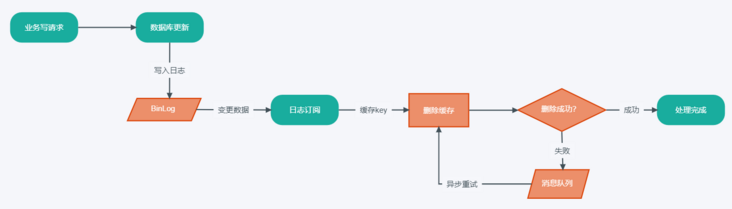
- 用户发起请求,需要写入更新数据
- 业务服务进行数据库更新操作完成业务请求
- 数据库操作写入BinLog日志
- 通过中间件订阅数据库BinLog日志(如:canel),获取需要更新缓存的key和数据
- 根据解析结果进行缓存删除,如果删除失败则放入消息队列
- 消费消息队列中的消息,获取需要重试的缓存key
- 重试缓存删除操作
总结
缓存和数据库一致性问题的出现在于高并发请求下缓存操作和数据库操作不是原子性的导致,虽然可以通过引入诸多的方案来保证数据的最终一致,但无论哪种方案都大大增加了系统的复杂度,同时引入更多问题。因此需要合理的评估业务,对数据一致性的敏感程度来选择合适的方案,没必要为了追求一致而一致。
reference
https://segmentfault.com/a/1190000040130178