
Technical journal
Kubernetes Network
Kubernetes网络模型
Kubernetes网络模型设计的基础原则:每个Pod拥有一个独立的IP地址,而且所有Pod都在一个可以直接连通、扁平的网络空间中。这种网络模型被称为IP-per-Pod模型。
NAT的作用是把内网的私有地址,转化为公有地址。使得内部网络上的(被设置为私有IP地址的)主机可以访问Internet。
IP-per-Pod模型使得:
- 所有的容器都可以在不用NAT的方式下同别的容器通讯;所有节点都可在不用NAT的方式下同所有容器通讯;容器的地址和别人看到的地址是同一个地址。
- Pod内部的所有container共享一个网络堆栈,包括IP地址、网络设备、配置等,即同一个Pod内的容器可以通过localhost来连接对方的端口。
Google设计的公有云GCE默认支持Kubernetes网络模型,亚马逊提供的公有云也支持这种网络模型。但是,我们在部署私有云来运行kubernetes+docker集群之前,需要自己搭建出符合kubernetes网络模型的网络环境。
Kubernetes网络依赖于Docker,而Docker的网络又离不开Linux OS内核特性的支持。
Docker Network
Docker 的网络实现其实就是利用了 Linux 上的网络命名空间和虚拟网络设备
首先,要实现网络通信,机器需要至少一个网络接口(物理接口或虚拟接口)来收发数据包;此外,如果不同子网之间要进行通信,需要路由机制。
Docker 中的网络接口默认都是虚拟的接口。虚拟接口的优势之一是转发效率较高。 Linux 通过在内核中进行数据复制来实现虚拟接口之间的数据转发,发送接口的发送缓存中的数据包被直接复制到接收接口的接收缓存中。对于本地系统和容器内系统看来就像是一个正常的以太网卡,只是它不需要真正同外部网络设备通信,速度要快很多。
Docker 容器网络就利用了这项技术。它在本地主机和容器内分别创建一个虚拟接口,并让它们彼此连通(这样的一对接口叫做 veth pair)。
Glossary
网络的命名空间
Linux 在网络栈中引入网络命名空间,将独立的网络协议栈隔离到不同的命名空间中,彼此间无法通信;Docker 利用这一特性,实现不容器间的网络隔离。
Veth 设备对
也叫虚拟网络接口对。Veth设备对的引入是为了实现在不同网络命名空间的通信。
Iptables/Netfilter
Netfilter 负责在内核中执行各种挂接的规则(过滤、修改、丢弃等),运行在内核 模式中;Iptables模式是在用户模式下运行的进程,负责协助维护内核中 Netfilter 的各种规则表;通过二者的配合来实现整个 Linux 网络协议栈中灵活的数据包处理机制。
网桥Bridge
网桥是一个二层网络设备,通过网桥可以将 linux 支持的不同的端口连接起来,并实现类似交换机那样的多对多的通信。
路由
Linux 系统包含一个完整的路由功能,当IP层在处理数据发送或转发的时候,会使用路由表来决定发往哪里。
docker网络实现
用过docker基本都知道,启动docker engine后,主机的网络设备里会有一个docker0的网关,而容器默认情况下会被分配在一个以docker0为网关的虚拟子网中。为了实现上述功能,docker主要用到了linux的Bridge、Network Namespace、VETH。
- doker的Bridge相当于是一个虚拟网桥,工作在第二层网络。也可以为它配置IP,工作在三层网络。docker0网关就是通过Bridge实现的。
- Network Namespace是网络命名空间,通过Network Namespace可以建立一些完全隔离的网络栈。比如通过
docker network create xxx就是在建立一个Network Namespace。 - VETH是虚拟网卡的接口对,可以把两端分别接在两个不同的Network Namespace中,实现两个原本隔离的Network Namespace的通信。
所以总结起来就是:Network Namespace做了容器和宿主机的网络隔离,Bridge分别在容器和宿主机建立一个网关,然后再用VETH将容器和宿主机两个网络空间连接起来。
CNM
基于上面的网络实现,docker的容器网络管理项目libnetwork提出了CNM(container network model)。
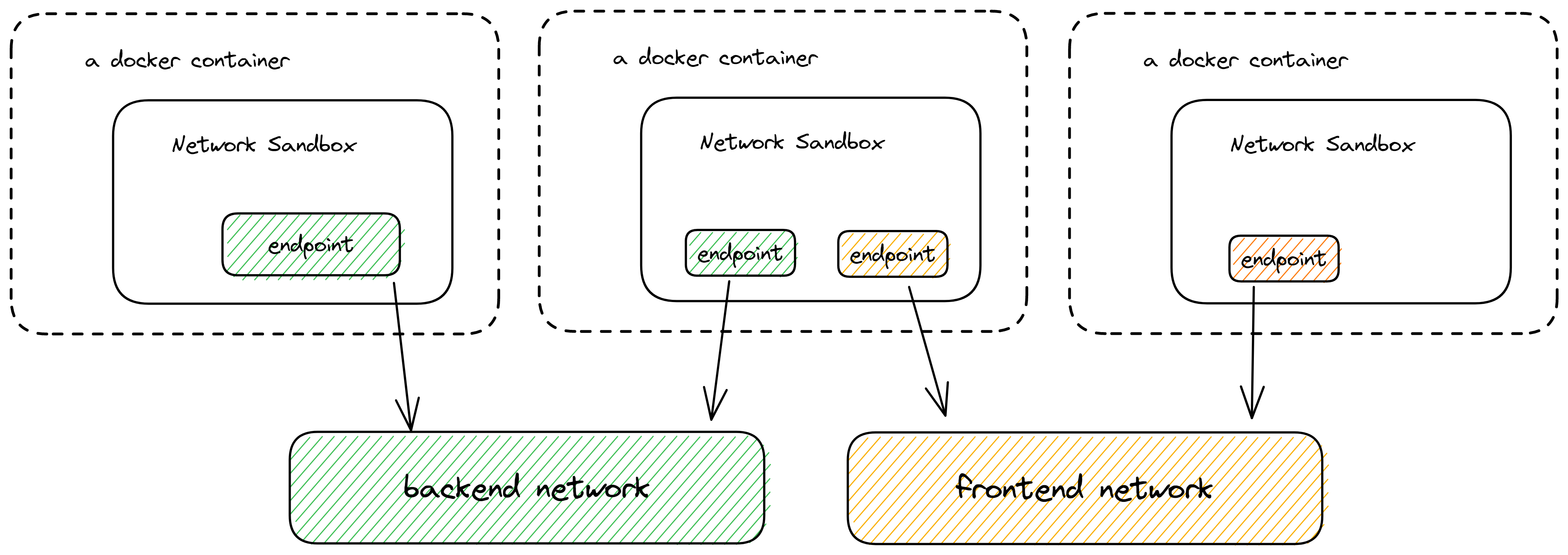
- Sandbox:每个沙盒包含一个容器网络栈(network stack)的配置,配置包括:容器的网口、路由表和DNS设置等。
- Endpoint:通过Endpoint,沙盒可以被加入到一个Network里。
- Network:一组能相互直接通信的Endpoints。
Sandbox对应于Network Namespace, Endpoint对应于VETH, Network对应于Bridge。
创建网络参数
Docker 创建一个容器的时候,会执行如下操作:
创建一对虚拟接口,分别放到本地主机和新容器中;
本地主机一端桥接到默认的 docker0 或指定网桥上,并具有一个唯一的名字,如 veth65f9;
容器一端放到新容器中,并修改名字作为 eth0,这个接口只在容器的命名空间可见;
从网桥可用地址段中获取一个空闲地址分配给容器的 eth0,并配置默认路由到桥接网卡 veth65f9。
完成这些之后,容器就可以使用 eth0 虚拟网卡来连接其他容器和其他网络。
可以在 docker run 的时候通过 --net 参数来指定容器的网络配置,有4个可选值:
--net=bridge这个是默认值,连接到默认的网桥。--net=host告诉 Docker 不要将容器网络放到隔离的命名空间中,即不要容器化容器内的网络。此时容器使用本地主机的网络,它拥有完全的本地主机接口访问权限。容器进程可以跟主机其它 root 进程一样可以打开低范围的端口,可以访问本地网络服务比如 D-bus,还可以让容器做一些影响整个主机系统的事情,比如重启主机。因此使用这个选项的时候要非常小心。如果进一步的使用--privileged=true,容器会被允许直接配置主机的网络堆栈。--net=container:NAME_or_ID让 Docker 将新建容器的进程放到一个已存在容器的网络栈中,新容器进程有自己的文件系统、进程列表和资源限制,但会和已存在的容器共享 IP 地址和端口等网络资源,两者进程可以直接通过lo环回接口通信。--net=none让 Docker 将新容器放到隔离的网络栈中,但是不进行网络配置。之后,用户可以自己进行配置。
Kubernetes 网络实现
Kubernetes网络有一个重要的基本设计原则:
每个Pod拥有唯一的IP
这个Pod IP被该Pod内的所有容器共享,并且其它所有Pod都可以路由到该Pod。每个Kubernetes节点上运行着一些”pause”容器。它们被称作“沙盒容器(sandbox containers)”,其唯一任务是保留并持有一个网络命名空间(netns),该命名空间被Pod内所有容器共享。通过这种方式,即使一个容器死掉,新的容器创建出来代替这个容器,Pod IP也不会改变。这种IP-per-pod模型的巨大优势是,Pod和底层主机不会有IP或者端口冲突。我们不用担心应用使用了什么端口。
这点满足后,Kubernetes唯一的要求是,这些Pod IP可被其它所有Pod访问,不管那些Pod在哪个节点。
节点内通信
第一步是确保同一节点上的Pod可以相互通信,然后可以扩展到跨节点通信、internet上的通信,等等。
在每个Kubernetes节点(本场景指的是Linux机器)上,都有一个根(root)命名空间(root是作为基准,而不是超级用户)– root netns(root network namespace)。主要的网络接口 eth0 就是在这个root netns下。
类似的,每个Pod都有其自身的netns(network namespace),通过一个虚拟的以太网对连接到root netns。这基本上就是一个管道对,一端在root netns内,另一端在Pod的netns内。
我们把Pod端的网络接口叫 eth0,这样Pod就不需要知道底层主机,它认为它拥有自己的根网络设备。另一端命名成比如 vethxxx。可以用 ifconfig 或者 ip a 命令列出你的节点上的所有这些接口。
节点上的所有Pod都会完成这个过程。这些Pod要相互通信,就要用到linux的以太网桥 cbr0 了。Docker使用了类似的网桥,称为docker0。你可以用 brctl show 命令列出所有网桥。
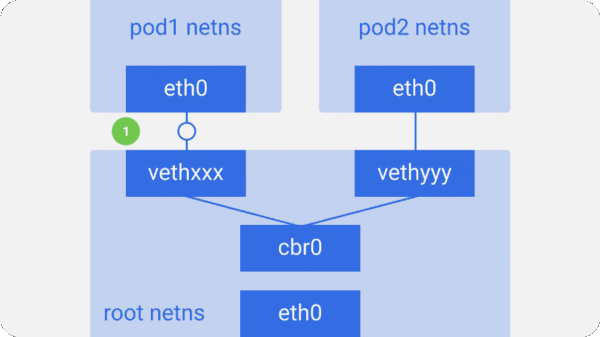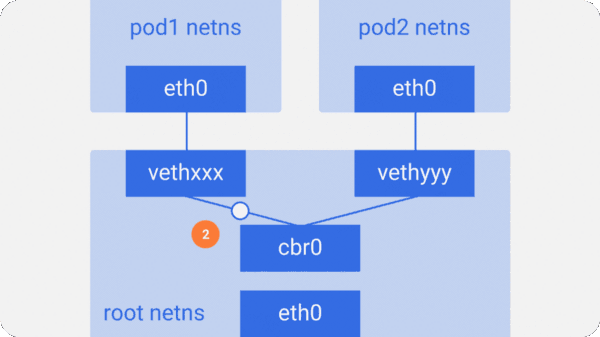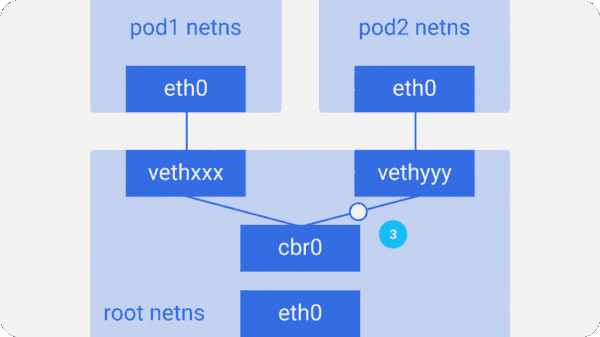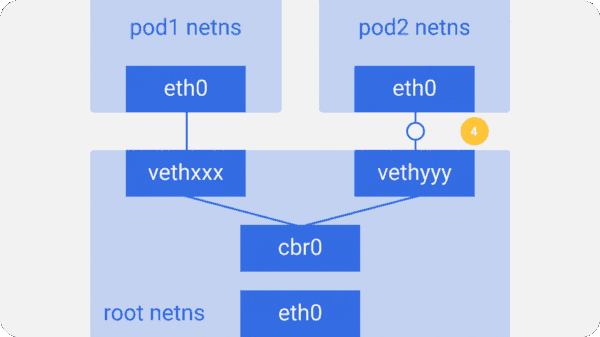
假设一个网络数据包要由pod1到pod2
- 它由pod1中netns的eth0网口离开,通过vethxxx进入root netns。
- 然后被传到cbr0,cbr0使用ARP请求,说“谁拥有这个IP”,从而发现目标地址。
- vethyyy说它有这个IP,因此网桥就知道了往哪里转发这个包。
- 数据包到达vethyyy,跨过管道对,到达pod2的netns。
这就是同一节点内容器间通信的流程。当然也可以用其它方式,但是无疑这是最简单的方式,同时也是Docker采用的方式。
不同节点间通信
正如前面提到,Pod也需要跨节点可达。Kubernetes不关心如何实现。我们可以使用L2(ARP跨节点),L3(IP路由跨节点,就像云提供商的路由表),Overlay网络,或者甚至信鸽。无所谓,只要流量能到达另一个节点的期望Pod就好。每个节点都为Pod IPs分配了唯一的CIDR块(一段IP地址范围),因此每个Pod都拥有唯一的IP,不会和其它节点上的Pod冲突。
大多数情况下,特别是在云环境上,云提供商的路由表就能确保数据包到达正确的目的地。我们在每个节点上建立正确的路由也能达到同样的目的。许多其它的网络插件通过自己的方式达到这个目的。
这里我们有两个节点,与之前看到的类似。每个节点有不同的网络命名空间、网络接口以及网桥。
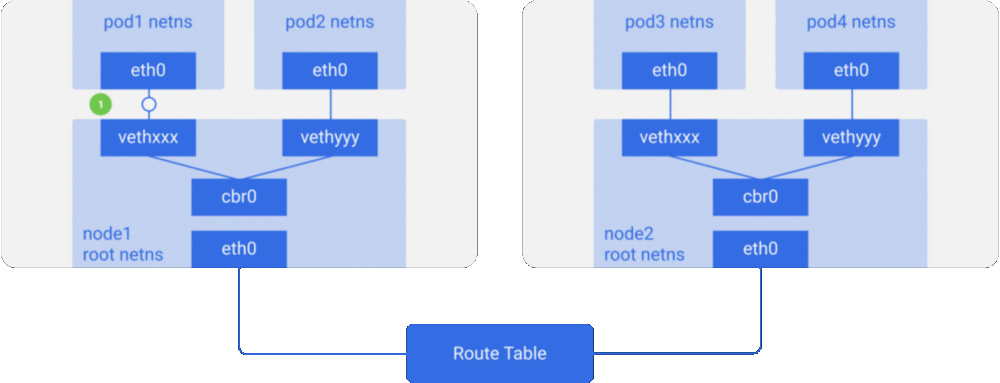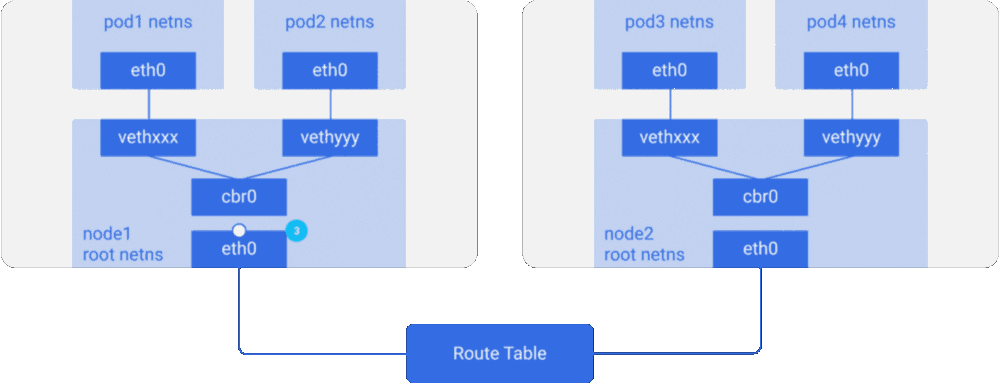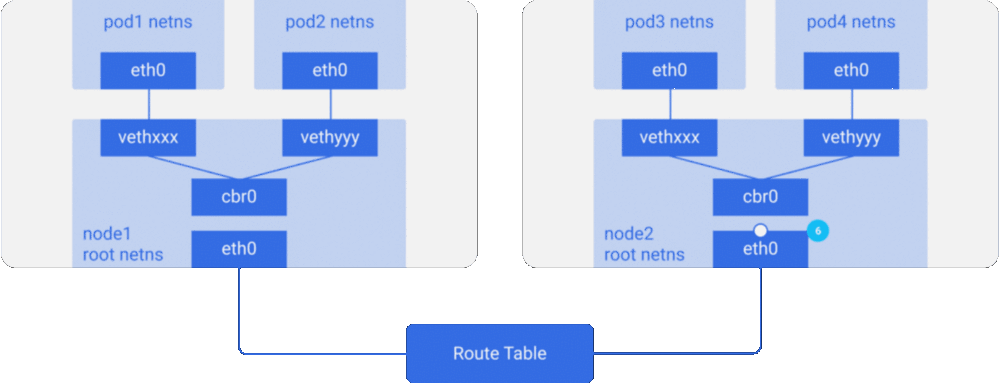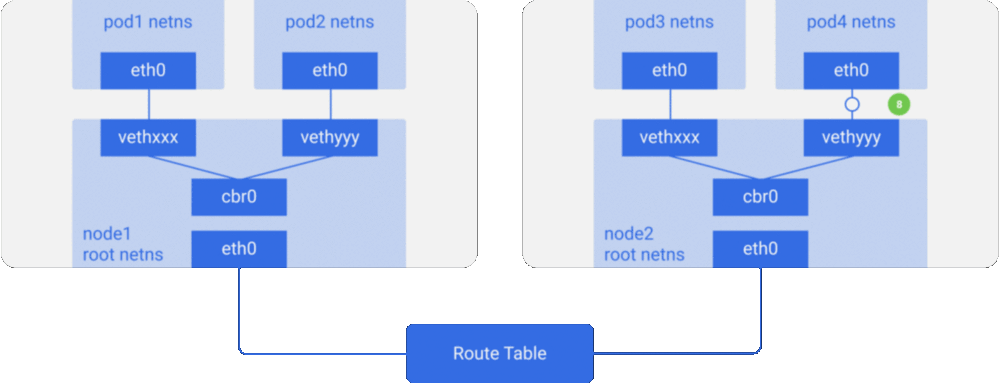
假设一个数据包要从pod1到达pod4(在不同的节点上)
- 它由pod1中netns的eth0网口离开,通过vethxxx进入root netns。
- 然后被传到cbr0,cbr0通过发送ARP请求来找到目标地址。
- 本节点上没有Pod拥有pod4的IP地址,根据路由判断数据包由cbr0 传到主网络接口 eth0.
- 数据包的源地址为pod1,目标地址为pod4,它以这种方式离开node1进入电缆。
- 路由表有每个节点的CIDR块的路由设定,它把数据包路由到CIDR块包含pod4的IP的节点。
- 因此数据包到达了node2的主网络接口eth0。现在即使pod4不是eth0的IP,数据包也仍然能转发到cbr0,因为节点配置了IP forwarding enabled。节点的路由表寻找任意能匹配pod4 IP的路由。它发现了 cbr0 是这个节点的CIDR块的目标地址。你可以用route -n命令列出该节点的路由表,它会显示cbr0的路由.
- 网桥接收了数据包,发送ARP请求,发现目标IP属于vethyyy。
- 数据包跨过管道对到达pod4。
Kube-proxy
Kube-proxy是一个简单的网络代理和负载均衡器,它的作用主要是负责Service的实现,具体来说,就是实现了内部从Pod到Service和外部的从NodePort向Service的访问。
总结
kubernetes网络由于它集群的特性,面对不同的服务器,不同的pod,那么其网络流程就可以分出不同的场景。
同一个pod的不同容器之间的通信
在kubernetes中每一个pod都会有一个根容器,这个根容器里面就会包含ip、端口等网络信息,每个pod都会有一个单独的根容器,你在后面加的容器都只会添加,不会改变pod的网络内容。官方内容是指在同一个pod当中的不同容器是共享网络命名空间的。所以在同一个pod的不同容器是可以直接通过localhost的方式直接访问的。
同一台机器的不同pod之间的通信
同一机器的pod网络,以下图为例,pod当中含有container1,container2两个容器和一个pause容器(也就是根容器)。图中有三个网卡设备,eth0是kubernetes集群主机的网卡设备,这个作为服务器之间通信的基本条件一般都会有。docker0是一个虚拟网桥,可以简单理解为一个虚拟交换机,它是支持该节点上的Pod之间进行IP寻址和互通的设备。veth0则是Pod1的虚拟网卡,是支持该Pod内容器互通和对外访问的虚拟设备。docker0网桥和veth0网卡,都是linux支持和创建的虚拟网络设备。Pod的IP是由docker0网桥分配的,例如上图docker0网桥的IP是172.17.0.1,它给第一个Pod1分配IP为172.17.0.2。如果该节点上再启一个Pod2,那么相应的分配IP为172.17.0.3,如果再启动Pod可依次类推。因为这些Pods都连在同一个网桥上,在同一个网段内,它们可以进行IP寻址和互通。
不同机器之间不同pod的通信
在不同机器之间网络通信时,docker0网桥就不能跨机器了,这个时候我们需要一个桥梁将两者关联起来,也就是cni网络插件,现在比较流行的是flannel和calico。以flannel为例,flannel会在每一台集群主机之中创建一个flannel0,flannel0给创建的pod分配一个和它同网段的ip,flannel0和主机ip做关联,这时不同主机的pod就可以通过flannel0进行通信。
Q&A
Q:A的Pod如何连接B的Pod? kube-dns起到什么作用? kube-dns如果调用kube-proxy?
A:这里说的A和B应当是指Service,A Service中Pod与B Service Pod之间的通信,可以在其容器的环境变量中定义Service IP或是Service Name来实现;由于Service IP提前不知道,使用引入kube-dns做服务发现,它的作用就是监听Service变化并更新DNS,即Pod通过服务名称可以查询DNS;kube-proxy是一个简单的网络代理和负载均衡器,它的作用主要是负责service的实现,具体来说,就是实现了内部从Pod到Service和外部的从NodePort向Service的访问,可以说kube-dns和kube-proxy都是为Service服务的。
Q:网络问题docker default是网桥模式(NAT) 如果用路由的模式,所以Pod的网关都会是docker 0 IP ? 那Pod 1与Pod 2之间也走路由 ,这会使路由表很大? Flannel 网络是不是可以把所有的Node上,相当于一个分布式交换机?
A:Docker实现跨主机通信可以通过桥接和路由的方式,桥接的方式是将docker0桥接在主机的网卡上,而路由直接通过主机网口转发出去;Kubernetes网络有Pod和Server,Pod网络实现的方式很多,可以参考CNI网络模型,Flannel实质上是一种“覆盖网络(Overlay Network)”,也就是将TCP数据包装在另一种网络包里面进行路由转发和通信。
Q:大规模容器集群如何保证安全? 主要从几个方面考虑?
A:一个大规模容器集群从安全性考虑来讲,可以分为几个方面:1、集群安全,包括集群高可用;2、访问安全,包括认证、授权、访问控制等;3、资源隔离,包括多租户等;4、网络安全,包括网络隔离、流量控制等;5、镜像安全,包括容器漏洞等;6、容器安全,包括端口暴露、privileged权限等。
Q:SVC如何进行客户端分流,A网段的访问Pod1 ,B网段的访问Pod2,C网段的访问Pod3,3个Pod都在SVC的Endpoint中?
A:内部从Pod到Service的实现是由kube-proxy(简单的网络代理和负载均衡器)来完成,kube-proxy默认采用轮询方法进行分配,也可以通过将service.spec.sessionAffinity设置为“ClientIP”(默认为“无”)来选择基于客户端IP的会话关联,目前还不能进行网段的指定。
Q:对于Ingress+HAProxy这种实现Service负载均衡的方式,Ingress controller轮询Service后面的Pods状态,并重新生成HAProxy配置文件,然后重启HAProxy,从而达到服务发现的目的。这种原理对于HAProxy来讲是不是服务会暂时间断。有没有好的替代方案?之前看到Golang实现的Træfik,可无缝对接Kubernetes,同时不需要Ingress了。方案可行么?
A:由于微服务架构以及Docker技术和Kubernetes编排工具最近几年才开始逐渐流行,所以一开始的反向代理服务器比如Nginx/HAProxy并未提供其支持,毕竟他们也不是先知,所以才会出现IngressController这种东西来做Kubernetes和前端负载均衡器如Nginx/HAProxy之间做衔接,即Ingress Controller的存在就是为了能跟Kubernetes交互,又能写 Nginx/HAProxy配置,还能 reload 它,这是一种折中方案;而最近开始出现的Traefik天生就是提供了对Kubernetes的支持,也就是说Traefik本身就能跟Kubernetes API交互,感知后端变化,因此在使用Traefik时就不需要Ingress Controller,此方案当然可行。
Q:1、一个POD里面的多个Container是同一个Service的?还是由不同的Service的组成? 是啥样的分配逻辑? 2、Flannel 是实现多个宿主机上的N多的Service以及Pod里面的各个Container的IP的唯一性么? 3、Kubernetes具备负载均衡的效果 。那是否就不用在考虑Nigix?
A:Pod是Kubernetes的基本操作单元,Pod包含一个或者多个相关的容器,Pod可以认为是容器的一种延伸扩展,一个Pod也是一个隔离体,而Pod内部包含的一组容器又是共享的(包括PID、Network、IPC、UTS);Service是Pod的路由代理抽象,能解决Pod之间的服务发现问题;Flannel的设计目的就是为集群中的所有节点重新规划IP地址的使用规则,从而使得不同节点上的容器能够获得“同属一个内网”且”不重复的”IP地址,并让属于不同节点上的容器能够直接通过内网IP通信;Kubernetes kube-proxy实现的是内部L4层轮询机制的负载均衡,要支持L4、L7负载均衡,Kubernetes也提供了Ingress组件,通过反向代理负载均衡器(Nginx/HAProxy)+Ingress Controller+Ingress可以实现对外服务暴露,另外使用Traefik方案来实现Service的负载均衡也是一种不错的选择。
Q:kube-proxy是怎样进行负载? Service虚拟IP存在哪里?
A:kube-proxy有2个模式实现负载均衡,一种是userspace,通过Iptables重定向到kube-proxy对应的端口上,然后由kube-proxy进一步把数据发送到其中的一个Pod上,另一种是Iptables,纯采用Iptables来实现负载均衡,kube-proxy默认采用轮询方法进行分配,也可以通过将service.spec.sessionAffinity设置为“ClientIP”(默认为“无”)来选择基于客户端IP的会话关联;Service Cluster IP它是一个虚拟IP,是由kube-proxy使用Iptables规则重新定向到其本地端口,再均衡到后端Pod的,通过 apiserver的启动参数–service-cluster-ip-range来设置,由kubernetes集群内部维护。
Q:Kubernetes网络复杂,如果要实现远程调试,该怎么做,端口映射的方式会有什么样的隐患?
A:Kubernetes网络这块采用的是CNI规范,网络插件化,非常灵活,不同的网络插件调试的方法也是不一样的;端口映射方式的最大隐患就是很容易造成端口冲突。
Q:RPC的服务注册,把本机IP注册到注册中心,如果在容器里面会注册那个虚拟IP,集群外面没法调用,有什么好的解决方案吗?
A:Kubernetes Service到Pod的通信是由kube-proxy代理分发,而Pod中容器的通信是通过端口,不同Service间通信可以通过DNS,不一定要使用虚拟IP。
Q:我现在才用的是CoreOS作为底层,所以网络采用的是Flannel 但是上层用Calico作为Network Policy,最近有一个Canal的结构和这个比较类似,能介绍一下么,可以的话,能详细介绍一下CNI原理和Callico的Policy实现么?
A:Canal不是很了解;CNI并不是网络实现,它是网络规范和网络体系,从研发的角度它就是一堆接口,关心的是网络管理的问题,CNI的实现依赖于两种Plugin,一种是CNI Plugin负责将容器connect/disconnect到host中的vbridge/vswitch,另一种是IPAM Plugin负责配置容器Namespace中的网络参数;Calico 的policy是基于Iptables,保证通过各个节点上的 ACLs 来提供workload 的多租户隔离、安全组以及其他可达性限制等功能。
Q:CNI是怎么管理网络的?或者说它跟网络方案之间是怎么配合的?
A:CNI并不是网络实现,它是网络规范和网络体系,从研发的角度它就是一堆接口,你底层是用Flannel也好、用Calico也好,它并不关心,它关心的是网络管理的问题,CNI的实现依赖于两种plugin,一种是CNI Plugin负责将容器connect/disconnect到host中的vbridge/vswitch,另一种是IPAM Plugin负责配置容器Namespace中的网络参数。
Q:Service是个实体组件么?那些个Service配置文件,什么部件来执行呢?
A:Services是Kubernetes的基本操作单元,是真实应用服务的抽象,Service IP范围在配置kube-apiserver服务的时候通过–service-cluster-ip-range参数指定,由Kubernetes集群自身维护。