What happens when you type a URL into your browser?
从输入一个 URL、按下回车到显示页面,中间发生了什么?这个问题既有广度,又有深度,很能考验一个人的知识体系。
网络上有很多资源,非常详细具体地解释了从底层到高层、从硬件到软件的原理。而本文更侧重于在同一个层次讨论浏览器、操作系统、服务器是如何交互的。
整体流程
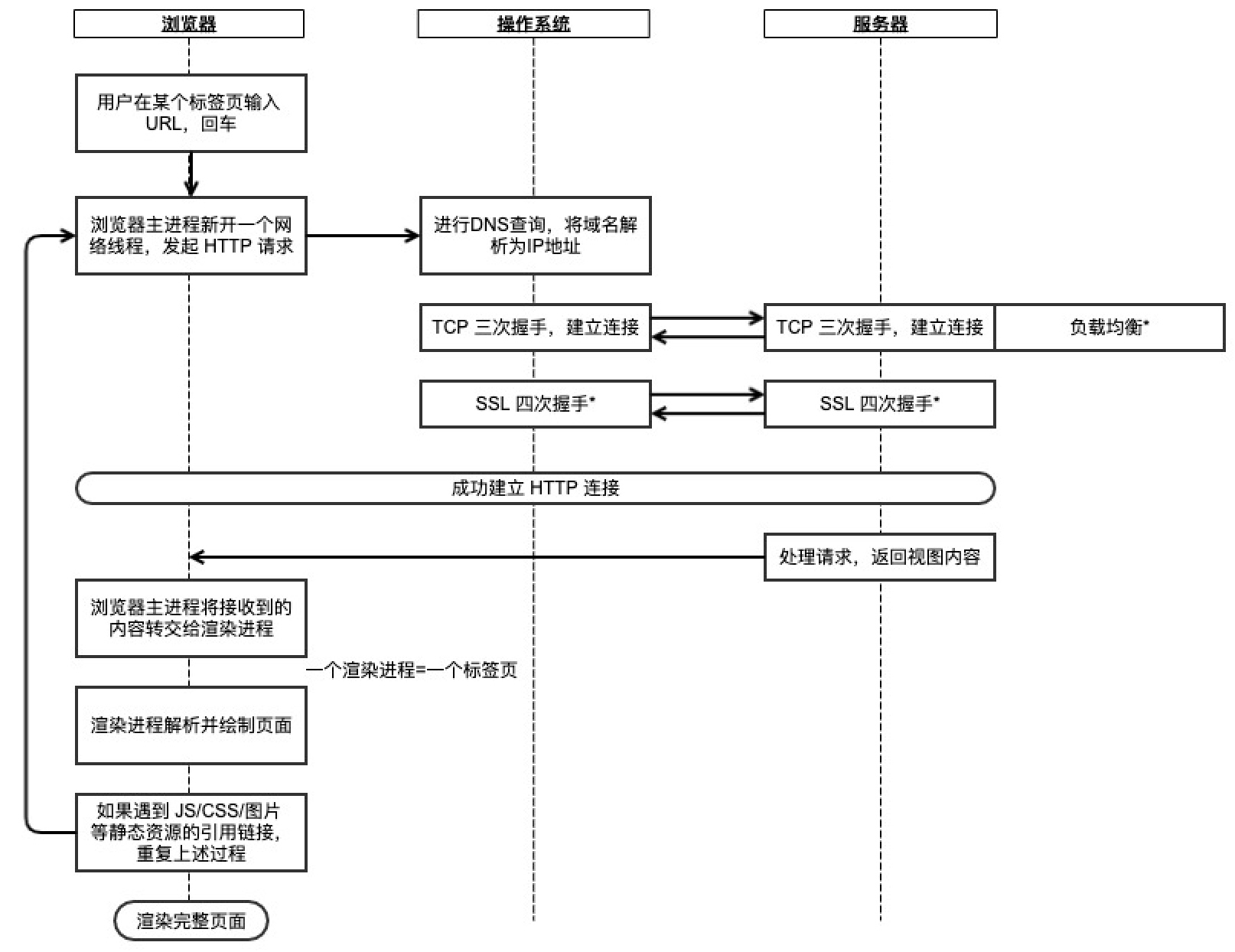
- 用户在某个标签页输入 URL 并回车后,浏览器主进程会新开一个网络线程,发起 HTTP 请求
- 浏览器会进行 DNS 查询,将域名解析为 IP 地址
- 浏览器获得 IP 地址后,向服务器请求建立 TCP 连接
- 浏览器向服务器发起 HTTP 请求
- 服务器处理请求,返回 HTTP 响应
- 浏览器的渲染进程解析并绘制页面
- 如果遇到 JS/CSS/图片 等静态资源的引用链接,重复上述过程,向服务器请求这些资源
browser
浏览器是多进程的。
浏览器只有一个主进程,又称 Browser 进程,负责创建/管理其他进程、显示浏览器主窗口、下载网络资源等。
每打开一个标签页,就创建了一个独立的浏览器渲染进程。浏览器渲染进程又称为浏览器内核、Renderer 进程,其内部是多线程的,负责页面渲染、脚本执行等。
浏览器的每一个网络请求,都需要主进程开辟一个单独的网络线程去处理。输入 URL 相当于一个网络请求,解析 HTML 时遇到 JS/CSS/图片等静态资源的引用链接,也需要分别请求。
浏览器的渲染流程:
- 解析 HTML 文件,构建 DOM 树,同时下载 CSS 等静态资源
- CSS 文件下载完成后,解析 CSS 文件,形成 CSSOM 树
- DOM 与 CSSOM 合并得到渲染树 Render Tree
- 计算渲染树中各个元素的尺寸、位置,这个过程称为回流 Reflow
- 浏览器将各个图层的信息发送给 GPU,GPU 绘制页面
进一步阅读:浏览器运行机制
- 浏览器的多进程模型
- 浏览器内核的多线程模型
- GUI 线程、JS 线程的阻塞关系
- JS 引擎的解析与执行过程
- JS 单线程模型、事件循环 Event-Loop
- …
server
负载均衡:大型的项目,往往是由多台服务器组成一个集群,以此应对庞大的并发访问量。这种情况下,用户的请求都会指向调度服务器,由调度服务器将请求分发给集群中的某台服务器 A,然后调度服务器会将 A 服务器的 HTTP 响应发送给用户。
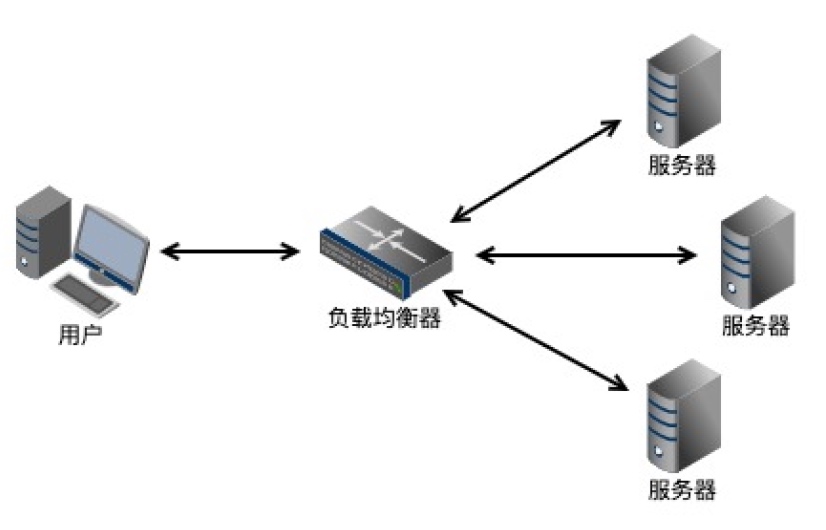
此外,后端还会经过安全认证、参数校验、中间件、执行业务代码、访问数据库等一系列操作,才能向用户返回结果。
网络协议
网络协议栈
DNS 原理
域名结构
互联网采用了层次树状结构的命名方法。任何一个连接在互联网上的主机或路由器,都有一个唯一的层次结构的名字,即域名。
域名的结构由标号序列组成,各标号之间用点隔开。类似于这样:“….三级域名.二级域名.顶级域名” 。各级域名由其上一级的域名管理机构管理,而最高级的顶级域名则由ICANN进行管理。
域名服务器
互联网上的DNS域名服务器也是按照层次划分的,每一个域名服务器都只对域名体系中的一部分进行管辖。根据域名服务器所起的作用,可以把域名服务器划分为四种不同的类型:
根域名服务器:根域名服务器是最高层次的域名服务器,也是最重要的域名服务器。根域名服务器知道所有顶级域名服务器的域名和 IP地址。如果本地域名服务器无法对域名进行解析,就首先求助于根域名服务器。
顶级域名服务器:顶级域名服务器负责管理在该服务器注册的所有二级域名。当收到 DNS 查询请求时,就给出相应的回答(可能是最后的结果,也可能是下一步需要查询的域名服务器的 IP 地址)。
权威域名服务器:负责一个区的域名服务器。当一个权限域名服务器还不能给出最后的查询回答时,就会告知发出查询请求的DNS客户,下一步应当找哪一个权威域名服务器。
本地域名服务器:本地域名服务器并不属于下图中的树状结构的DNS域名服务器,但是它对域名系统非常重要。当一个主机发出DNS查询请求时,这个查询请求报文就发送给本地域名服务器。每一个互联网服务提供者ISP都可以拥有一个本地域名服务器。
DNS 查询过程
DNS 是应用层的协议,作用是将域名转化为 IP,以供传输层建立 TCP 连接。
整体流程:
浏览器搜索自身的 DNS 缓存
搜索操作系统的 DNS 缓存
读取本地的 host 文件
路由器缓存:路由器缓存路由器映射表;
向本地 DNS 服务器进行查询:ISP(Internet Service Provider), 是互联网服务提供商的简称。ISP有专门的DNS服务器对应DNS查询请求。
向域服务器发送请求,没找到的话递归到下一级的域服务器继续查找(域服务器递归寻找)。直到找到返回;
本地域名服务器把返回的结果保存到缓存,以备下一次使用,同时将该结果反馈给客户端,客户端通过这个 IP 地址即可访问目标Web服务器。
如果本地DNS服务器无法查询到,则根据本地DNS服务器设置的转发器进行查询。若未用转发模式,则迭代查找过程如下图:
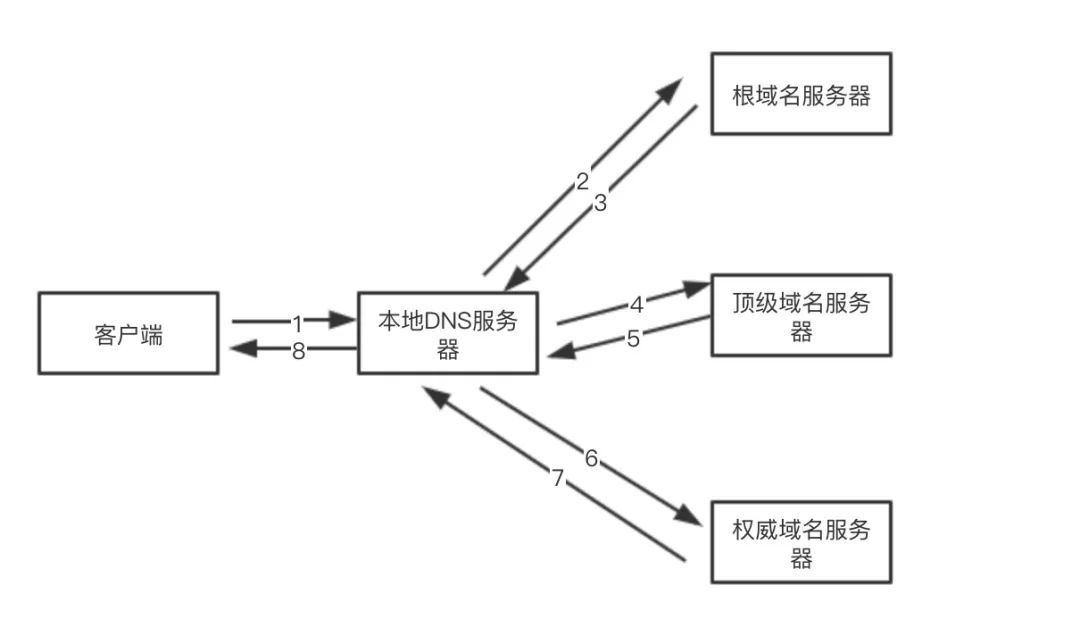
在查找过程中,有以下优化点:
- DNS存在着多级缓存,从离浏览器的距离排序的话,有以下几种: 浏览器缓存,系统缓存,路由器缓存,IPS服务器缓存,根域名服务器缓存,顶级域名服务器缓存,主域名服务器缓存。
- 在域名和 IP 的映射过程中,给了应用基于域名做负载均衡的机会,可以是简单的负载均衡,也可以根据地址和运营商做全局的负载均衡。
TCP连接
TCP 是传输层协议,HTTP 协议通过 TCP 协议发送数据。之所以选择 TCP,是因为 HTTP 对数据的准确性要求高,TCP 能够提供可靠的交付。
首先,判断是不是https的,如果是,则HTTPS其实是HTTP + SSL / TLS 两部分组成,也就是在HTTP上又加了一层处理加密信息的模块。服务端和客户端的信息传输都会通过TLS进行加密,所以传输的数据都是加密后的数据。
进行三次握手,建立TCP连接。
- 第一次握手:建立连接。客户端发送连接请求报文段,将SYN位置为1,Sequence Number为x;然后,客户端进入SYN_SEND状态,等待服务器的确认;
- 第二次握手:服务器收到SYN报文段。服务器收到客户端的SYN报文段,需要对这个SYN报文段进行确认,设置Acknowledgment Number为x+1(Sequence Number+1);同时,自己还要发送SYN请求信息,将SYN位置为1,Sequence Number为y;服务器端将上述所有信息放到一个报文段(即SYN+ACK报文段)中,一并发送给客户端,此时服务器进入SYN_RECV状态;
- 第三次握手:客户端收到服务器的SYN+ACK报文段。然后将Acknowledgment Number设置为y+1,向服务器发送ACK报文段,这个报文段发送完毕以后,客户端和服务器端都进入ESTABLISHED状态,完成TCP三次握手。
完成了之后,客户端和服务器端就可以开始传送数据。
关闭TCP连接
- 第一次分手:主机1(可以使客户端,也可以是服务器端),设置Sequence Number和Acknowledgment Number,向主机2发送一个FIN报文段;此时,主机1进入FIN_WAIT_1状态;这表示主机1没有数据要发送给主机2了;
- 第二次分手:主机2收到了主机1发送的FIN报文段,向主机1回一个ACK报文段,Acknowledgment Number为Sequence Number加1;主机1进入FIN_WAIT_2状态;主机2告诉主机1,我”同意”你的关闭请求;
- 第三次分手:主机2向主机1发送FIN报文段,请求关闭连接,同时主机2进入LAST_ACK状态;
- 第四次分手:主机1收到主机2发送的FIN报文段,向主机2发送ACK报文段,然后主机1进入TIME_WAIT状态;主机2收到主机1的ACK报文段以后,就关闭连接;此时,主机1等待2MSL后依然没有收到回复,则证明Server端已正常关闭,那好,主机1也可以关闭连接了。
SSL 四次握手
SSL 位于传输层和应用层之间,TCP 和 HTTP 之间。SSL 协议的目的是,为通信双方提供一种在不安全的网络环境中,安全地协商一个密钥的方法。
SSL 实现的核心是非对称式密码学。非对称密码包含两个部分:公钥和私钥,一个用作加密,另一个则用作解密。使用其中一个密钥把明文加密后所得的密文,只能用相对应的另一个密钥才能解密得到原本的明文;甚至连最初用来加密的密钥也不能用作解密。
HTTPS 本质上就是 HTTP + SSL。通过 SSL 四次握手过程,客户端和服务端会商定一个共同的随机密钥,用来对称加密。握手结束后,双方都会使用这个约定的随机密钥来加密、解密会话内容,使用的完全是普通的 HTTP 协议。
SSL握手过程
- 第一阶段 建立安全能力 包括协议版本 会话Id 密码构件 压缩方法和初始随机数
- 第二阶段 服务器发送证书 密钥交换数据和证书请求,最后发送请求-相应阶段的结束信号
- 第三阶段 如果有证书请求客户端发送此证书 之后客户端发送密钥交换数据 也可以发送证书验证消息
- 第四阶段 变更密码构件和结束握手协议
HTTP 的长连接与短连接
HTTP/1.0 默认使用的是短连接。也就是说,浏览器每请求一个静态资源,就建立一次连接,任务结束就中断连接。
HTTP/1.1 默认使用的是长连接。长连接是指在一个网页打开期间,所有网络请求都使用同一条已经建立的连接。当没有数据发送时,双方需要发检测包以维持此连接。长连接不会永久保持连接,而是有一个保持时间。实现长连接要客户端和服务端都支持长连接。
长连接的优点:TCP 三次握手时会有 1.5 RTT 的延迟,以及建立连接后慢启动(slow-start)特性,当请求频繁时,建立和关闭 TCP 连接会浪费时间和带宽,而重用一条已有的连接性能更好。
长连接的缺点:长连接会占用服务器的资源。
HTTP 2.0
HTTP 2.0 的三大特性是头部压缩、服务端推送、多路复用。
HTTP 1.1 允许通过同一个连接发起多个请求。但是由于 HTTP 1.X 使用文本格式传输数据,服务端必须按照客户端请求到来的顺序,串行返回数据。此外,HTTP 1.1 中浏览器会限制同时发起的最大连接数,超过该数量的连接会被阻塞。
HTTP 2 引入了多路复用,允许通过同一个连接发起多个请求,并且可以并行传输数据。HTTP 2 使用二进制数据帧作为传输的最小单位,每个帧标识了自己属于哪个流,每个流对应一个请求。服务端可以并行地传输数据,而接收端可以根据帧中的顺序标识,自行合并数据。
在 HTTP 1.1 中,由于浏览器限制每个域名下最多同时有 6 个请求,其余请求会被阻塞,因此我们通常使用多个域名(比如 CDN)来提高浏览器的下载速度。HTTP 2 就不再需要这样优化了。
同理,在 HTTP 1.1 中,我们会将多个 JS 文件、CSS 文件等打包成一个文件,将多个小图片合并为雪碧图,目的是减少 HTTP 请求数。HTTP 2 也不需要这样优化了。
HTTP 缓存
浏览器可以将已经请求过的资源(如图片、JS 文件)缓存下来,下次再次请求相同的资源时,直接从缓存读取。
浏览器采用的缓存策略有两种:强制缓存、协商缓存。浏览器根据第一次请求资源时返回的 HTTP 响应头来选择缓存策略。
强制缓存:为资源设置一个过期时间,只要资源没有过期,就读取浏览器的缓存。强制缓存不需要向服务器发起请求,浏览器直接返回 200(from cache)。
协商缓存:浏览器携带缓存资源的元信息,向服务器发起请求,由服务器决定是否使用缓存。如果协商缓存生效,服务器返回 304 和 Not Modified;如果协商缓存失效,服务器返回 200 和请求结果。
协商缓存的原理是:服务端根据资源的元信息,判断浏览器缓存的资源在服务器上是否有改动。元信息有两种,一种是资源的上次修改时间,另一种是资源 Hash 值。前者实现简单,但是精确度低,文件修改时间只能以秒记;后者精确度高,但是性能低,需要计算哈希值。