
Technical journal
How to design a thread safe map
Map 是一种很常见的数据结构,用于存储一些无序的键值对。在主流的编程语言中,默认就自带它的实现。C、C++ 中的 STL 就实现了 Map,JavaScript 中也有 Map,Java 中有 HashMap,Swift 和 Python 中有 Dictionary,Go 中有 Map,Objective-C 中有 NSDictionary、NSMutableDictionary。
上面这些 Map 都是线程安全的么?答案是否定的,并非全是线程安全的。那如何能实现一个线程安全的 Map 呢?想回答这个问题,需要先从如何实现一个 Map 说起。
选用什么数据结构实现 Map ?
Map 是一个非常常用的数据结构,一个无序的 key/value 对的集合,其中 Map 所有的 key 都是不同的,然后通过给定的 key 可以在常数时间 O(1) 复杂度内查找、更新或删除对应的 value。
要想实现常数级的查找,应该用什么来实现呢?读者应该很快会想到哈希表。确实,Map 底层一般都是使用数组来实现,会借用哈希算法辅助。对于给定的 key,一般先进行 hash 操作,然后相对哈希表的长度取模,将 key 映射到指定的地方。
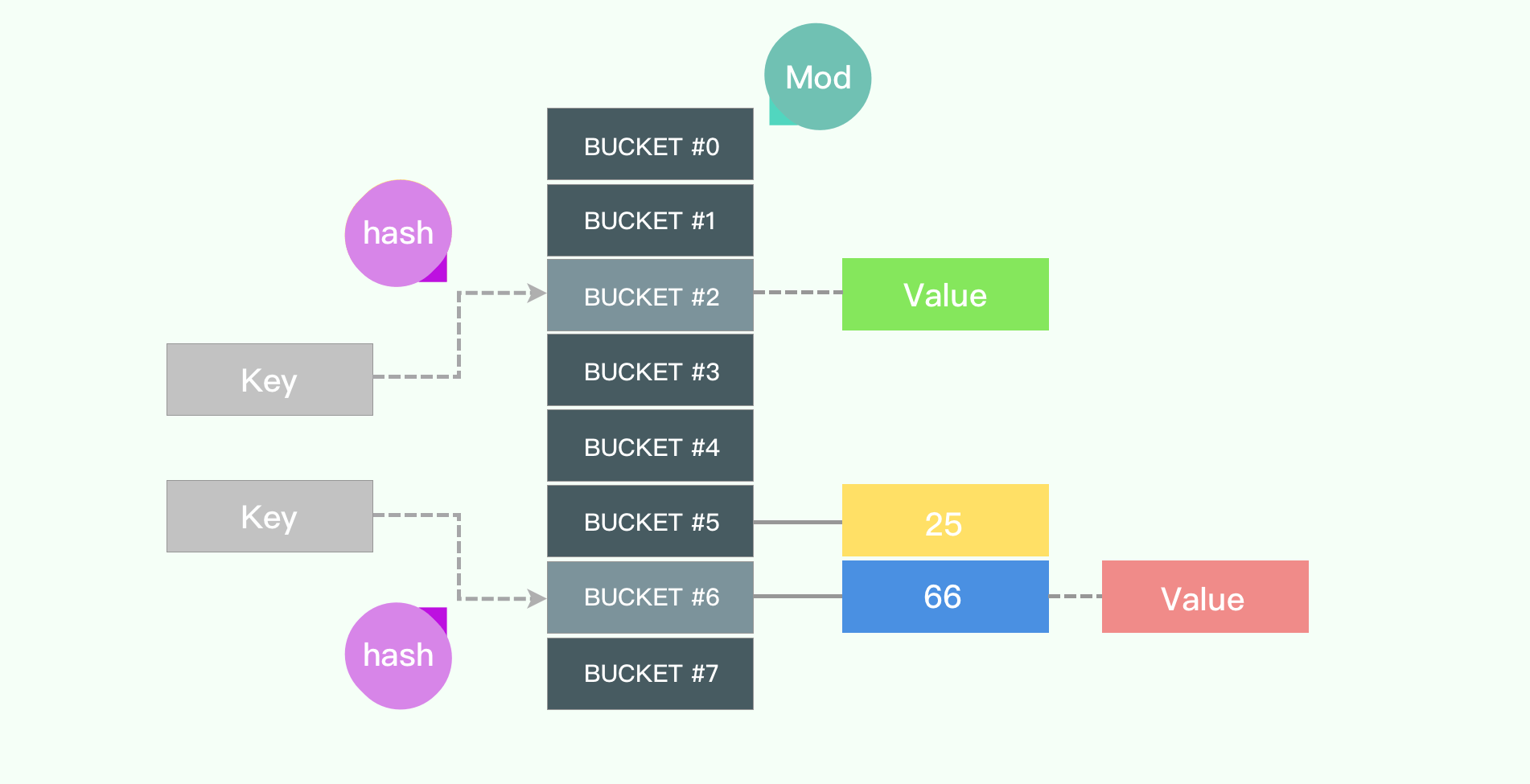
哈希算法有很多种,选哪一种更加高效呢?
哈希函数
MD5 和 SHA1 可以说是目前应用最广泛的 Hash 算法,而它们都是以 MD4 为基础设计的。
MD4(RFC 1320) 是 MIT 的Ronald L. Rivest 在 1990 年设计的,MD 是 Message Digest(消息摘要) 的缩写。它适用在32位字长的处理器上用高速软件实现——它是基于 32位操作数的位操作来实现的。
MD5(RFC 1321) 是 Rivest 于1991年对 MD4 的改进版本。它对输入仍以512位分组,其输出是4个32位字的级联,与 MD4 相同。MD5 比 MD4 来得复杂,并且速度较之要慢一点,但更安全,在抗分析和抗差分方面表现更好。
SHA1 是由 NIST NSA 设计为同 DSA 一起使用的,它对长度小于264的输入,产生长度为160bit 的散列值,因此抗穷举 (brute-force)
性更好。SHA-1 设计时基于和 MD4 相同原理,并且模仿了该算法。
常用的 hash 函数有 SHA-1,SHA-256,SHA-512,MD5 。这些都是经典的 hash 算法。在现代化生产中,还会用到现代的 hash 算法。下面列举几个,进行性能对比,最后再选其中一个源码分析一下实现过程。
Jenkins Hash 和 SpookyHash
1997年 Bob Jenkins 在《 Dr. Dobbs Journal》杂志上发表了一片关于散列函数的文章《A hash function for hash Table lookup》。这篇文章中,Bob 广泛收录了很多已有的散列函数,这其中也包括了他自己所谓的“lookup2”。随后在2006年,Bob 发布了 lookup3。lookup3 即为 Jenkins Hash。更多有关 Bob’s 散列函数的内容请参阅维基百科:Jenkins hash function。memcached的 hash 算法,支持两种算法:jenkins, murmur3,默认是 jenkins。
2011年 Bob Jenkins 发布了他自己的一个新散列函数 SpookyHash(这样命名是因为它是在万圣节发布的)。它们都拥有2倍于 MurmurHash 的速度,但他们都只使用了64位数学函数而没有32位版本,SpookyHash 给出128位输出。
MurmurHash
MurmurHash 是一种非加密型哈希函数,适用于一般的哈希检索操作。
Austin Appleby 在2008年发布了一个新的散列函数——MurmurHash。其最新版本大约是 lookup3 速度的2倍(大约为1 byte/cycle),它有32位和64位两个版本。32位版本只使用32位数学函数并给出一个32位的哈希值,而64位版本使用了64位的数学函数,并给出64位哈希值。根据Austin的分析,MurmurHash具有优异的性能,虽然 Bob Jenkins 在《Dr. Dobbs article》杂志上声称“我预测 MurmurHash 比起lookup3要弱,但是我不知道具体值,因为我还没测试过它”。MurmurHash能够迅速走红得益于其出色的速度和统计特性。当前的版本是MurmurHash3,Redis、Memcached、Cassandra、HBase、Lucene都在使用它。
CityHash 和 FramHash
这两种算法都是 Google 发布的字符串算法。
CityHash 是2011年 Google 发布的字符串散列算法,和 murmurhash 一样,属于非加密型 hash 算法。CityHash 算法的开发是受到了 MurmurHash 的启发。其主要优点是大部分步骤包含了至少两步独立的数学运算。现代 CPU 通常能从这种代码获得最佳性能。CityHash 也有其缺点:代码较同类流行算法复杂。Google 希望为速度而不是为了简单而优化,因此没有照顾较短输入的特例。Google发布的有两种算法:cityhash64 与 cityhash128。它们分别根据字串计算 64 和 128 位的散列值。这些算法不适用于加密,但适合用在散列表等处。CityHash 的速度取决于CRC32 指令,目前为SSE 4.2(Intel Nehalem及以后版本)。
相比 Murmurhash 支持32、64、128bit, Cityhash 支持64、128、256bit 。
2014年 Google 又发布了 FarmHash,一个新的用于字符串的哈希函数系列。FarmHash 从 CityHash 继承了许多技巧和技术,是它的后继。FarmHash 有多个目标,声称从多个方面改进了 CityHash。与 CityHash 相比,FarmHash 的另一项改进是在多个特定于平台的实现之上提供了一个接口。这样,当开发人员只是想要一个用于哈希表的、快速健壮的哈希函数,而不需要在每个平台上都一样时,FarmHash 也能满足要求。目前,FarmHash 只包含在32、64和128位平台上用于字节数组的哈希函数。未来开发计划包含了对整数、元组和其它数据的支持。
xxHash
xxHash 是由 Yann Collet 创建的非加密哈希函数。它最初用于 LZ4 压缩算法,作为最终的错误检查签名的。该 hash 算法的速度接近于 RAM 的极限。并给出了32位和64位的两个版本。现在它被广泛使用在PrestoDB、RocksDB、MySQL、ArangoDB、PGroonga、Spark 这些数据库中,还用在了 Cocos2D、Dolphin、Cxbx-reloaded 这些游戏框架中,
下面这有一个性能对比的实验。测试环境是 Open-Source SMHasher program by Austin Appleby ,它是在 Windows 7 上通过 Visual C 编译出来的,并且它只有唯一一个线程。CPU 内核是 Core 2 Duo @3.0GHz。
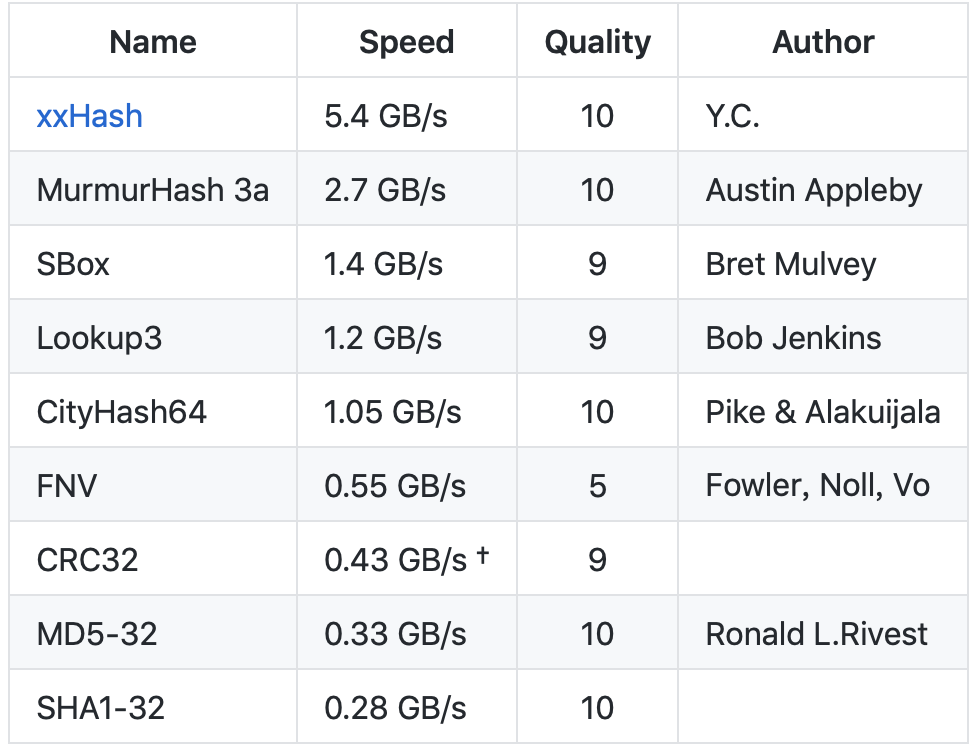
上表里面的 hash 函数并不是所有的 hash 函数,只列举了一些常见的算法。第二栏是速度的对比,可以看出来速度最快的是 xxHash 。第三栏是哈希的质量,哈希质量最高的有5个,全是5星,xxHash、MurmurHash 3a、CityHash64、MD5-32、SHA1-32 。从表里的数据看,哈希质量最高,速度最快的还是 xxHash。
xxhash的官网实现为C语言的版本,可以编译为库,也可以直接头文件inline:
https://github.com/Cyan4973/xxHash
另外也有C++17的纯模板单头文件实现:
https://github.com/RedSpah/xxhash_cpp
memhash
这个哈希算法笔者没有在网上找到很明确的作者信息。只在 Google 的 Go 的文档上有这么几行注释,说明了它的灵感来源:
1 | // Hashing algorithm inspired by |
那么接下来就来看看 memhash 是怎么对字符串进行哈希的。
1 | const ( |
m1、m2、m3、m4 是4个随机选的奇数,作为哈希的乘法因子。
1 | // used in hash{32,64}.go to seed the hash function |
在这个初始化的函数中,初始化了2个数组,数组里面装的都是随机的 hashkey。在 386、 amd64、非 nacl 的平台上,会用 aeshash 。这里会把随机的 key 生成好,存入到 aeskeysched 数组中。同理,hashkey 数组里面也会随机好4个数字。最后都按位与了一个1,就是为了保证生成出来的随机数都是奇数。
接下来举个例子,来看看 memhash 究竟是如何计算哈希值的。
1 | func main() { |
为了简单起见,这里用笔者的名字为例算出哈希值,种子简单一点设置成3。
第一步计算 h 的值。
1 | h := uint32(seed + s*hashkey[0]) |
这里假设 hashkey[0] = 1,那么 h 的值为 3 + 7 * 1 = 10 。由于 s < 8,那么就会进行以下的处理:
1 | case s <= 8: |
readUnaligned32()函数会把传入的 unsafe.Pointer 指针进行2次转换,先转成 *uint32 类型,然后再转成 *(*uint32) 类型。
1 | func rotl_15(x uint32) uint32 { |
这个函数里面对入参进行了两次位移操作。最后将两次位移的结果进行逻辑或运算。
AES Hash
在上面分析 Go 的 hash 算法的时候,我们可以看到它对 CPU 是否支持 AES 指令集进行了判断,当 CPU 支持 AES 指令集的时候,它会选用 AES Hash 算法,当 CPU 不支持 AES 指令集的时候,换成 memhash 算法。
AES 指令集全称是高级加密标准指令集(或称英特尔高级加密标准新指令,简称AES-NI)是一个 x86指令集架构 的扩展,用于 Intel 和 AMD微处理器 。
利用 AES 实现 Hash 算法性能会很优秀,因为它能提供硬件加速。
具体代码实现如下,汇编程序,注释见下面程序中:
1 | // aes hash 算法通过 AES 硬件指令集实现 |
最终的 hash 的实现都在 aeshashbody 中:
1 | // AX: 数据 |
哈希冲突处理
链表数组法
链表数组法比较简单,每个键值对表长取模,如果结果相同,用链表的方式依次往后插入。
将冲突位置的元素构造成链表。添加数据发生冲突时,将元素追加到链表。
开放地址法 —— 线性探测
线性探测的规则是 hi = ( h(k) + i ) MOD M。举个例子,i = 1,M = 9。
这种处理冲突的方法,一旦发生冲突,就把位置往后加1,直到找到一个空的位置。
开放地址法 —— 平方探测
线性探测的规则是 h0 = h(k) ,hi = ( h0 + i * i ) MOD M。
平方探测的发生冲突以后添加的值为查找次数的平方,在线性探测的基础上,加了一个二次曲线。当发生冲突以后,不再是加一个线性的参数,而是加上探测次数的平方。
平方探测有一个需要注意的是,M的大小有讲究。如果M不是奇素数,那么就可能出现下面这样的问题,即使哈希表里面还有空的位置,但是却有元素找不到要插入的位置。
举例,假设 M = 10,待插入的键值集合是{0,1,4,5,6,9,10},当前面6个键值插入哈希表中以后,10就再也无法插入了。
哈希表的扩容策略
随着哈希表装载因子的变大,发生碰撞的次数变得越来也多,哈希表的性能变得越来越差。对于单独链表法实现的哈希表,尚可以容忍,但是对于开放寻址法,这种性能的下降是不能接受的,因此对于开放寻址法需要寻找一种方法解决这个问题。
在实际应用中,解决这个问题的办法是动态的增大哈希表的长度,当装载因子超过某个阈值时增加哈希表的长度,自动扩容。每当哈希表的长度发生变化之后,所有 key 在哈希表中对应的下标索引需要全部重新计算,不能直接从原来的哈希表中拷贝到新的哈希表中。必须一个一个计算原来哈希表中的 key 的哈希值并插入到新的哈希表中。这种方式肯定是达不到生产环境的要求的,因为时间复杂度太高了,O(n),数据量一旦大了,性能就会很差。Redis 想了一种方法,就算是触发增长时也只需要常数时间 O(1) 即可完成插入操作。解决办法是分多次、渐进式地完成的旧哈希表到新哈希表的拷贝而不是一次拷贝完成。
负载因子
负载因子的值是条目数占用哈希桶比例,当负载因子超过理想值时,哈希表会进行扩容。比如哈希表理想值 0.75,初始容量 16,当条目超过 12 后哈希表会进行扩容重新哈希。0.6 和 0.75 是通常合理的负载因子。
影响哈希表性能的两个主要因素
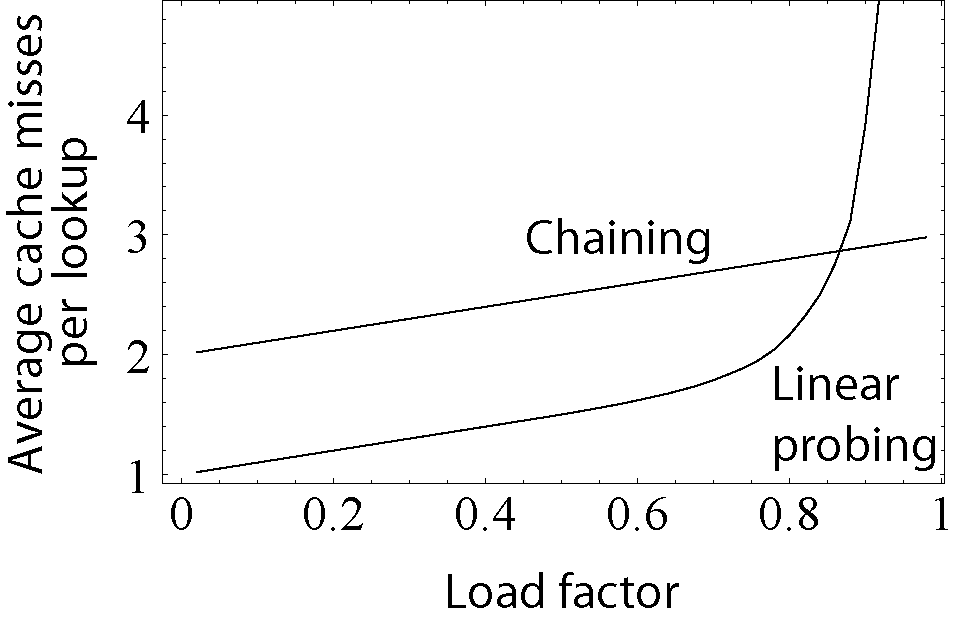
- 缓存丢失。随着负载因子的增加缓存丢失数量上升,而搜索和插入性能会因此大幅下降。
- 扩容重新哈希。调整大小是一项极其耗时的任务。设置合适的负载因子可以控制扩容次数。
下图展示了随着负载因子增加,缓存丢失的数量开始上升,0.8后开始迅速攀升。
什么时候扩容?
那么什么时候需要扩容?答案也很简单:1.初始化后放入元素时 2.达到阈值时
创建对象以后,
HashMap并不是立即初始化table,而是在第一次放入元素时,才会初始化table,这很HashMap节省内存得一种机制,而table的初始化其实是resize方法实现的。达到阈值时,这个就比较有意思,所谓阈值,就是
HashMap中threshold这个属性,阈值的计算方式很简单,基本上就是capacity * loadFactor,这里我觉得capacity应该称为理论容量,是因为正常情况下达到阈值就扩容了,达到阈值时HashMap认为哈希冲突的次数会不能接受,因此需要扩容。
因为这里是以JDK1.8源码作为样本分析的,JDK1.7中还存在rehash方法,但是JDK1.8中已经改名叫resize方法了。
红黑树优化
Java 在 JDK1.8 对 HashMap 底层的实现再次进行了优化。
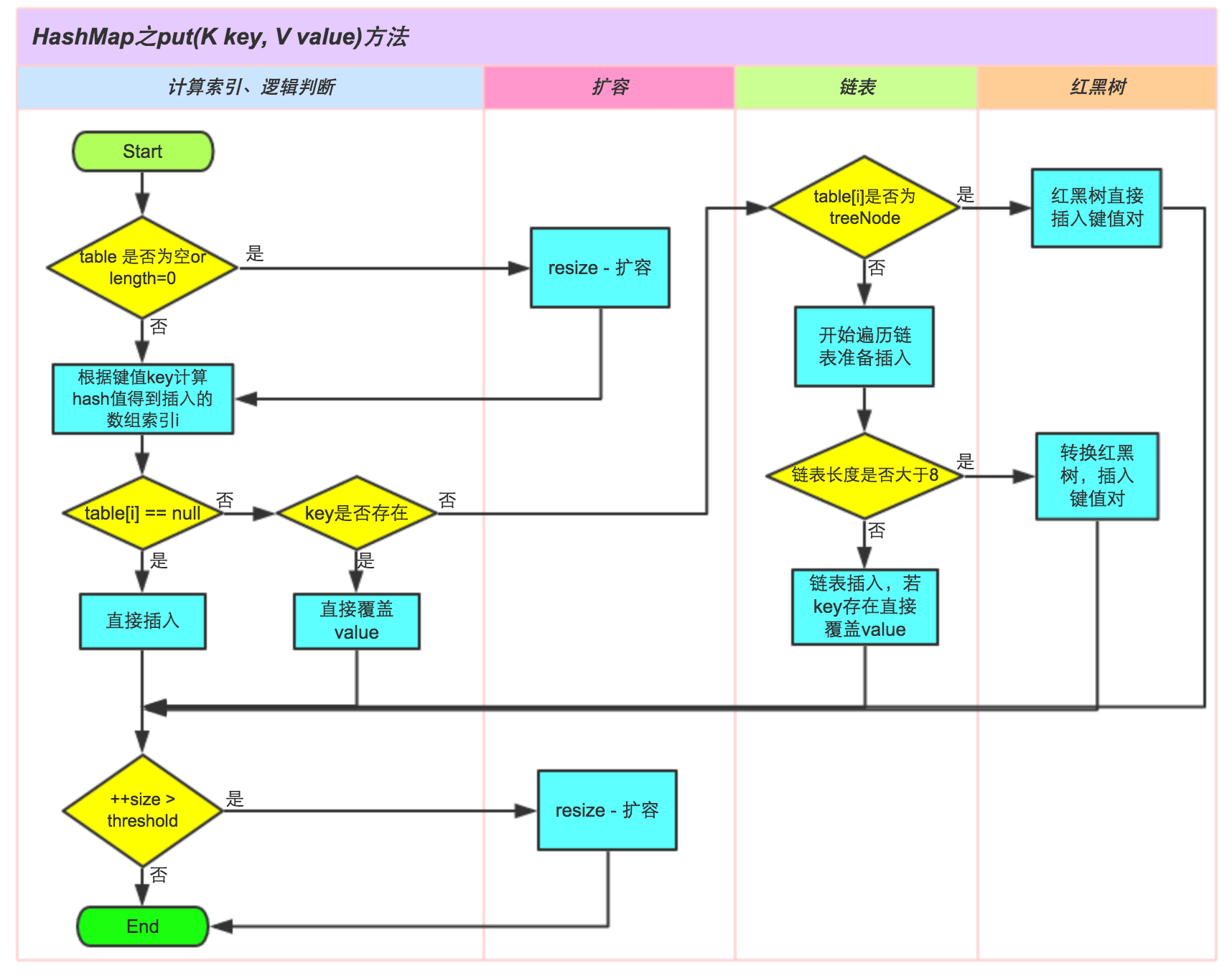
Java 底层初始桶的个数是16个,负载因子默认是0.75,也就是说当键值第一次达到12个的时候就会进行扩容 resize。扩容的临界值在64,当超过了64以后,并且冲突节点为8或者大于8,这个时候就会触发红黑树转换。为了防止底层链表过长,链表就转换为红黑树。换句话说,当桶的总个数没有到64个的时候,即使链表长为8,也不会进行红黑树转换。如果节点小于6个,红黑树又会重新退化成链表。
当然这里之所以选择用红黑树来进行优化,保证最坏情况不会退化成O(n),红黑树能保证最坏时间复杂度也为 O(log n)。
在美团博客中也提到了,Java 在 JDK1.8 中还有一个值得学习的优化。Java 在 rehash 的键值节点迁移过程中,不需要再次计算一次 hash 计算!由于使用了2次幂的扩展(指长度扩为原来2倍),所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。看下图可以明白这句话的意思,n 为 table 的长度,图(a)表示扩容前的 key1 和 key2 两种 key 确定索引位置的示例,图(b)表示扩容后 key1 和 key2 两种 key 确定索引位置的示例,其中 hash1 是 key1 对应的哈希与高位运算结果。
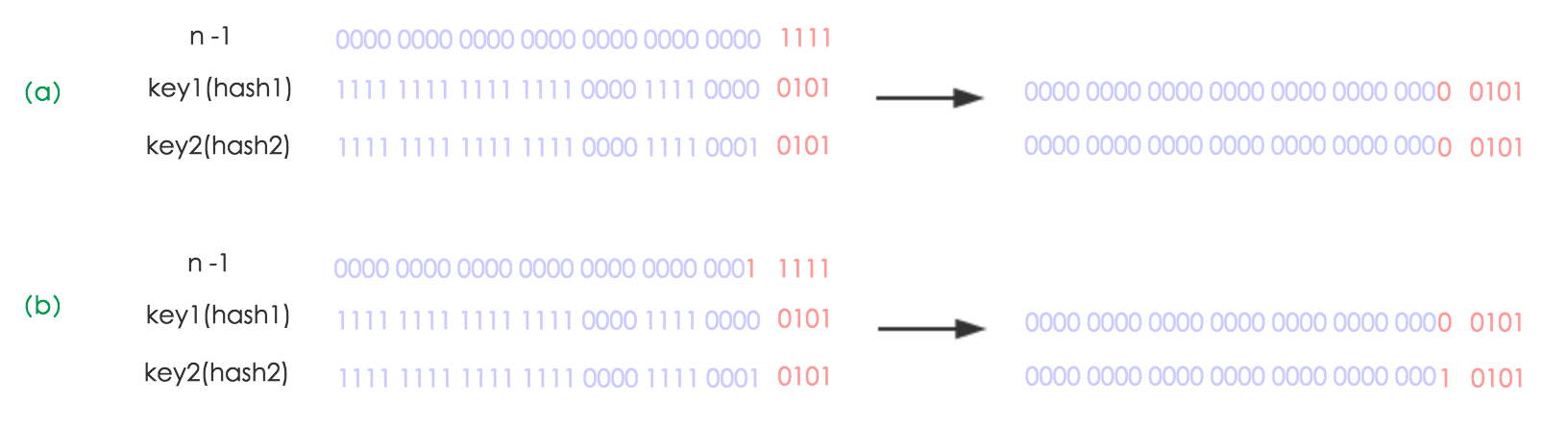
元素在重新计算 hash 之后,因为 n 变为2倍,那么 n-1 的 mask 范围在高位多1bit(红色),因此新的 index 就会发生这样的变化:
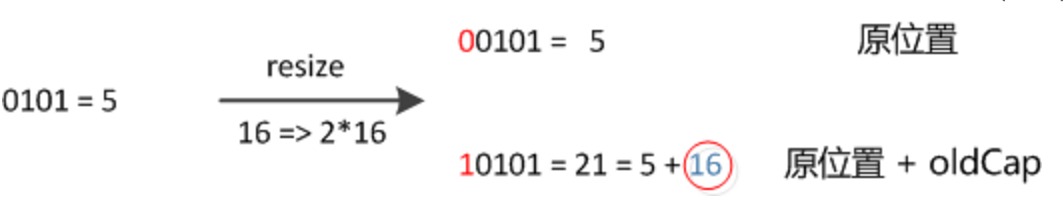
所以在扩容以后,就只需要看扩容容量以后那个位上的值为0,还是为1,如果是0,代表索引不变,如果是1,代表的是新的索引值等于原来的索引值加上 oldCap 即可,这样就不需要再次计算一次 hash 了。
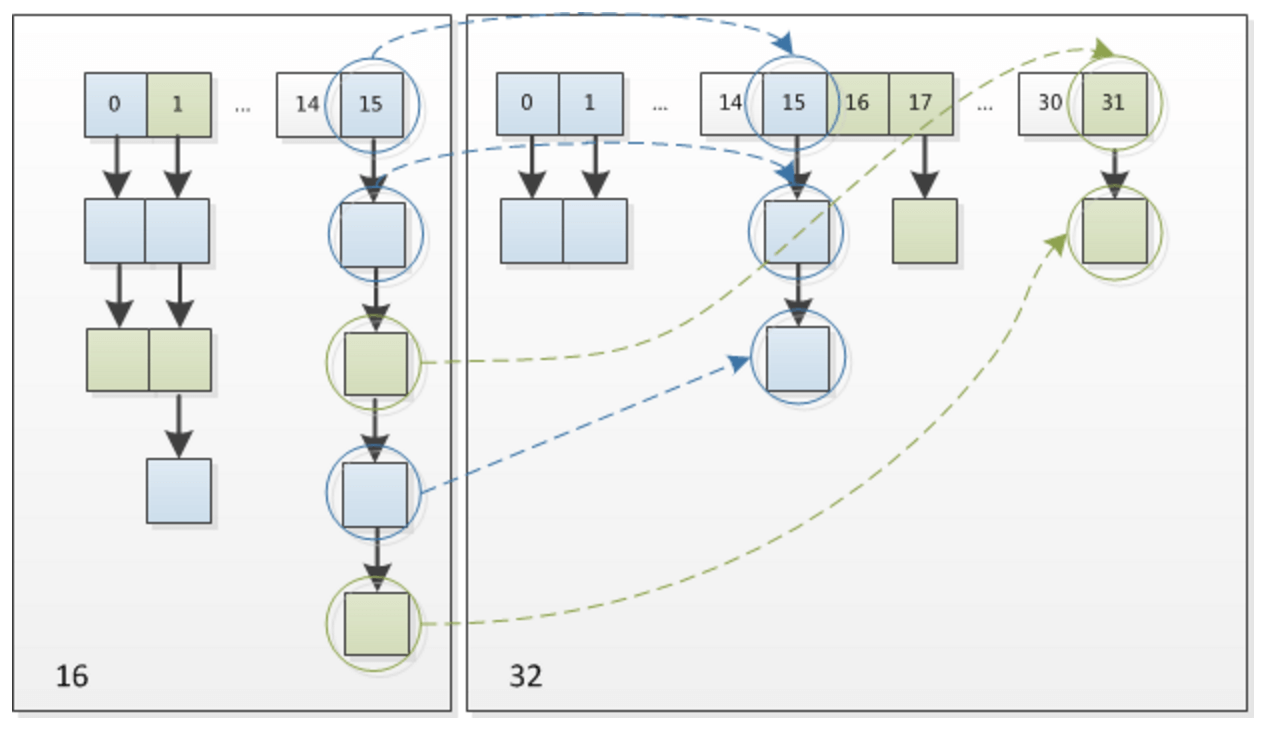
上图是把16扩容到32的情况。
Go 中 Map 的具体实现举例
Go 中的 Map 的底层实现进行分析,对一个 Map 的具体实现和重要的几个操作,添加键值,删除键值,扩容策略进行举例。
Go 定义了一些常量。
1 | const ( |
这里值得说明的一点是触发扩容操作的临界值6.5是怎么得来的。这个值太大会导致overflow buckets过多,查找效率降低,过小会浪费存储空间。
据 Google 开发人员称,这个值是一个测试的程序,测量出来选择的一个经验值。
Go 中 map header 的定义:
1 | type hmap struct { |
在 Go 的 map header 结构中,也包含了2个指向桶数组的指针,buckets 指向新的桶数组,oldbuckets 指向旧的桶数组。这点和 Redis 字典中也有两个 dictht 数组类似。
hmap 的最后一个字段是一个指向 mapextra 结构的指针,它的定义如下:
1 | type mapextra struct { |
如果一个键值对没有找到对应的指针,那么就会把它们先存到溢出桶 overflow 里面。在 mapextra 中还有一个指向下一个可用的溢出桶的指针。
溢出桶 overflow 是一个数组,里面存了2个指向 *bmap 数组的指针。overflow[0] 里面装的是 hmap.buckets 。overflow[1] 里面装的是 hmap.oldbuckets。
再看看桶的数据结构的定义,bmap 就是 Go 中 map 里面桶对应的结构体类型。
1 | type bmap struct { |
桶的定义比较简单,里面就只是包含了一个 uint8 类型的数组,里面包含8个元素。这8个元素存储的是 hash 值的高8位。
在 tophash 之后的内存布局里还有2块内容。紧接着 tophash 之后的是8对 键值 key- value 对。并且排列方式是 8个 key 和 8个 value 放在一起。
8对 键值 key- value 对结束以后紧接着一个 overflow 指针,指向下一个 bmap。从此也可以看出 Go 中 map是用链表的方式处理 hash 冲突的。
为何 Go 存储键值对的方式不是普通的 key/value、key/value、key/value……这样存储的呢?它是键 key 都存储在一起,然后紧接着是 值value 都存储在一起,为什么会这样呢?

在 Redis 中,当使用 REDIS_ENCODING_ZIPLIST 编码哈希表时, 程序通过将键和值一同推入压缩列表, 从而形成保存哈希表所需的键-值对结构,如上图。新添加的 key-value 对会被添加到压缩列表的表尾。
这种结构有一个弊端,如果存储的键和值的类型不同,在内存中布局中所占字节不同的话,就需要对齐。比如说存储一个 map[int64]int8 类型的字典。
Go 为了节约内存对齐的内存消耗,于是把它设计成上图所示那样。
如果 map 里面存储了上万亿的大数据,这里节约出来的内存空间还是比较可观的。
新建 Map
makemap 新建了一个 Map,如果入参 h 不为空,那么 map 的 hmap 就是入参的这个 hmap,如果入参 bucket 不为空,那么这个 bucket 桶就作为第一个桶。
1 | func makemap(t *maptype, hint int64, h *hmap, bucket unsafe.Pointer) *hmap { |
新建一个 map 最重要的就是分配内存并初始化哈希表,在 B 不为0的情况下,还会初始化 mapextra 并且会 buckets 会被重新生成。
1 | func makeBucketArray(t *maptype, b uint8) (buckets unsafe.Pointer, nextOverflow *bmap) { |
这里的 newarray 就已经是 mallocgc 了。
从上述代码里面可以看出,只有当 B >=4 的时候,makeBucketArray 才会生成 nextOverflow 指针指向 bmap,从而在 Map 生成 hmap 的时候才会生成 mapextra 。
当 B = 3 ( B < 4 ) 的时候,初始化 hmap 只会生成8个桶。
当 B = 4 ( B >= 4 ) 的时候,初始化 hmap 的时候还会额外生成 mapextra ,并初始化 nextOverflow。mapextra 的 nextOverflow 指针会指向第16个桶结束,第17个桶的首地址。第17个桶(从0开始,也就是下标为16的桶)的 bucketsize - sys.PtrSize 地址开始存一个指针,这个指针指向当前整个桶的首地址。这个指针就是 bmap 的 overflow 指针。
当 B = 5 ( B >= 4 ) 的时候,初始化 hmap 的时候还会额外生成 mapextra ,并初始化 nextOverflow。这个时候就会生成总共34个桶了。同理,最后一个桶大小减去一个指针的大小的地址开始存储一个 overflow 指针。
查找 Key
在 Go 中,如果字典里面查找一个不存在的 key ,查找不到并不会返回一个 nil ,而是返回当前类型的零值。比如,字符串就返回空字符串,int 类型就返回 0 。
1 | func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer { |
具体实现代码如上,详细解释见代码。
查找 key 的全过程,首先计算出 key 对应的 hash 值,hash 值对 B 取余。
这里有一个优化点。m % n 这步计算,如果 n 是2的倍数,那么可以省去这一步取余操作。
1 | m % n = m & ( n - 1 ) |
这样优化就可以省去耗时的取余操作了。这里例子中计算完取出来是 0010 ,也就是2,于是对应的是桶数组里面的第3个桶。为什么是第3个桶呢?首地址指向第0个桶,往下偏移2个桶的大小,于是偏移到了第3个桶的首地址了,具体实现可以看上述代码。
hash 的低 B 位决定了桶数组里面的第几个桶,hash 值的高8位决定了这个桶数组 bmap 里面 key 存在 tophash 数组的第几位了。hash 的高8位用来和 tophash 数组里面的每个值进行对比,如果高8位和 tophash[i] 不等,就直接比下一个。如果相等,则取出 bmap 里面对应完整的 key,再比较一次,看是否完全一致。
整个查找过程优先在 oldbucket 里面找(如果存在 lodbucket 的话),找完再去新 bmap 里面找。
为何这里要加入 tophash 多一次比较呢?
tophash 的引入是为了加速查找的。由于它只存了 hash 值的高8位,比查找完整的64位要快很多。通过比较高8位,迅速找到高8位一致hash 值的索引,接下来再进行一次完整的比较,如果还一致,那么就判定找到该 key 了。
如果找到了 key 就返回对应的 value。如果没有找到,还会继续去 overflow 桶继续寻找,直到找到最后一个桶,如果还没有找到就返回对应类型的零值。
插入 Key
插入 key 的过程和查找 key 的过程大体一致。
1 | func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer { |
插入 key 的过程中和查找 key 有几点不同,需要注意:
如果找到要插入的 key ,只需要直接更新对应的 value 值就好了。
如果没有在 bmap 中没有找到待插入的 key ,这么这时分几种情况。
情况一: bmap 中还有空位,在遍历 bmap 的时候预先标记空位,一旦查找结束也没有找到 key,就把 key 放到预先遍历时候标记的空位上。
情况二:bmap中已经没有空位了。这个时候 bmap 装的很满了。此时需要检查一次最大负载因子是否已经达到了。如果达到了,立即进行扩容操作。扩容以后在新桶里面插入 key,流程和上述的一致。如果没有达到最大负载因子,那么就在新生成一个bmap,并把前一个 bmap 的 overflow 指针指向新的 bmap。在扩容过程中,oldbucke t是被冻结的,查找 key 时会在 oldbucket 中查找,但不会在 oldbucket 中插入数据。如果在 oldbucket 是找到了相应的key,做法是将它迁移到新 bmap 后加入 evalucated 标记。
其他流程和查找 key 基本一致,这里就不再赘述了。
删除 Key
1 | func mapdelete(t *maptype, h *hmap, key unsafe.Pointer) { |
删除操作主要流程和查找 key 流程也差不多,找到对应的 key 以后,如果是指针指向原来的 key,就把指针置为 nil。如果是值就清空它所在的内存。还要清理 tophash 里面的值最后把 map 的 key 总个数计数器减1 。
如果在扩容过程中,删除操作会在扩容以后在新的 bmap 里面删除。
查找的过程依旧会一直遍历到链表的最后一个 bmap 桶。
增量翻倍扩容
这部分算是整个 Map 实现比较核心的部分了。我们都知道 Map 在不断的装载 Key 值的时候,查找效率会变的越来越低,如果此时不进行扩容操作的话,哈希冲突使得链表变得越来越长,性能也就越来越差。扩容势在必行。
但是扩容过程中如果阻断了 Key 值的写入,在处理大数据的时候会导致有一段不响应的时间,如果用在高实时的系统中,那么每次扩容都会卡几秒,这段时间都不能相应任何请求。这种性能明显是不能接受的。所以要既不影响写入,也同时要进行扩容。这个时候就应该增量扩容了。
这里增量扩容其实用途已经很广泛了,之前举例的 Redis 就采用的增量扩容策略。
接下来看看 Go 是怎么进行增量扩容的。
在 Go 的 mapassign 插入 Key 值、mapdelete 删除 key 值的时候都会检查当前是否在扩容中。
1 | func growWork(t *maptype, h *hmap, bucket uintptr) { |
从这里我们可以看到,每次执行一次 growWork 会迁移2个桶。一个是当前的桶,这算是局部迁移,另外一个是 hmap 里面指向的 nevacuate 的桶,这算是增量迁移。
在插入 Key 值的时候,如果当前在扩容过程中,oldbucket 是被冻结的,查找时会先在 oldbucket 中查找,但不会在oldbucket中插入数据。只有在 oldbucket 找到了相应的 key,那么将它迁移到新 bucket 后加入 evalucated 标记。
在删除 Key 值的时候,如果当前在扩容过程中,优先查找 bucket,即新桶,找到一个以后把它对应的 Key、Value 都置空。如果 bucket 里面找不到,才会去 oldbucket 中去查找。
每次插入 Key 值的时候,都会判断一下当前装载因子是否超过了 6.5,如果达到了这个极限,就立即执行扩容操作 hashGrow。这是扩容之前的准备工作。
1 | func hashGrow(t *maptype, h *hmap) { |
hashGrow 操作算是扩容之前的准备工作,实际拷贝的过程在 evacuate 中。
hashGrow 操作会先生成扩容以后的新的桶数组。新的桶数组的大小是之前的2倍。然后 hmap 的 buckets 会指向这个新的扩容以后的桶,而 oldbuckets 会指向当前的桶数组。
处理完 hmap 以后,再处理 mapextra,nextOverflow 的指向原来的 overflow 指针,overflow 指针置为 null。
到此就做好扩容之前的准备工作了。
1 | func evacuate(t *maptype, h *hmap, oldbucket uintptr) { |
上述函数就是迁移过程最核心的拷贝工作了。
整个迁移过程并不难。这里需要说明的是 x ,y 代表的意义。由于扩容以后,新的桶数组是原来桶数组的2倍。用 x 代表新的桶数组里面低位的那一半,用 y 代表高位的那一半。其他的变量就是一些标记了,游标和标记 key - value 原来所在的位置。详细的见代码注释。
旧的桶数组里面的桶在迁移到新的桶中,并且新的桶也在不断的写入新的 key 值。一直拷贝键值对,直到旧桶中所有的键值都拷贝到了新的桶中。最后一步就是释放旧桶,oldbuckets 的指针置为 null。到此,一次迁移过程就完全结束了。
等量扩容
严格意义上这种方式并不能算是扩容。但是函数名是 Grow,姑且暂时就这么叫吧。
在 go1.8 的版本开始,添加了 sameSizeGrow,当 overflow buckets 的数量超过一定数量 (2^B) 但装载因子又未达到 6.5 的时候,此时可能存在部分空的bucket,即 bucket 的使用率低,这时会触发sameSizeGrow,即 B 不变,但走数据迁移流程,将 oldbuckets 的数据重新紧凑排列提高 bucket 的利用率。当然在 sameSizeGrow 过程中,不会触发loadFactorGrow。
Map 实现中的一些优化
在 Redis 中,采用增量式扩容的方式处理哈希冲突。当平均查找长度超过 5 的时候就会触发增量扩容操作,保证 hash 表的高性能。
同时 Redis 采用头插法,保证插入 key 值时候的性能。
在 Java 中,当桶的个数超过了64个以后,并且冲突节点为8或者大于8,这个时候就会触发红黑树转换。这样能保证链表在很长的情况下,查找长度依旧不会太长,并且红黑树保证最差情况下也支持 O(log n) 的时间复杂度。
Java 在迁移之后有一个非常好的设计,只需要比较迁移之后桶个数的最高位是否为0,如果是0,key 在新桶内的相对位置不变,如果是1,则加上桶的旧的桶的个数 oldCap 就可以得到新的位置。
在 Go 中优化的点比较多:
- 哈希算法选用高效的 memhash 算法 和 CPU AES指令集。AES 指令集充分利用 CPU 硬件特性,计算哈希值的效率超高。
- key - value 的排列设计成 key 放在一起,value 放在一起,而不是key,value成对排列。这样方便内存对齐,数据量大了以后节约内存对齐造成的一些浪费。
- key,value 的内存大小超过128字节以后自动转成存储一个指针。
- tophash 数组的设计加速了 key 的查找过程。tophash 也被复用,用来标记扩容操作时候的状态。
- 用位运算转换求余操作,m % n ,当 n = 1 << B 的时候,可以转换成 m & (1 << B - 1) 。
- 增量式扩容。
- 等量扩容,紧凑操作。
- Go 1.9 版本以后,Map 原生就已经支持线程安全。(在下一章中重点讨论这个问题)
当然 Go 中还有一些需要再优化的地方:
- 在迁移的过程中,当前版本不会重用 overflow 桶,而是直接重新申请一个新的桶。这里可以优化成优先重用没有指针指向的 overflow 桶,当没有可用的了,再去申请一个新的。这一点作者已经写在了 TODO 里面了。
- 动态合并多个 empty 的桶。
- 当前版本中没有 shrink 操作,Map 只能增长而不能收缩。这块 Redis 有相关的实现。
线程安全
线程安全就是如果你的代码块所在的进程中有多个线程在同时运行,而这些线程可能会同时运行这段代码。如果每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的。
如果代码块中包含了对共享数据的更新操作,那么这个代码块就可能是非线程安全的。但是如果代码块中类似操作都处于临界区之中,那么这个代码块就是线程安全的。
通常有以下两类避免竞争条件的方法来实现线程安全,避免共享状态和线程同步:
避免共享状态
可重入 Re-entrancy
通常在线程安全的问题中,最常见的代码块就是函数。让函数具有线程安全的最有效的方式就是使其可重入。如果某个进程中所有线程都可以并发的对函数进行调用,并且无论他们调用该函数的实际执行情况怎么样,该函数都可以产生预期的结果,那么就可以说这个函数是可重入的。
如果一个函数把共享数据作为它的返回结果或者包含在它返回的结果中,那么该函数就肯定不是一个可重入的函数。任何内含了操作共享数据的代码的函数都是不可重入的函数。
为了实现线程安全的函数,把所有代码都置放于临界区中是可行的。但是互斥量的使用总会耗费一定的系统资源和时间,使用互斥量的过程总会存在各种博弈和权衡。所以请合理使用互斥量保护好那些涉及共享数据操作的代码。
注意:可重入只是线程安全的充分不必要条件,并不是充要条件。这个反例在下面会讲到。
线程本地存储
如果变量已经被本地化,所以每个线程都有自己的私有副本。这些变量通过子程序和其他代码边界保留它们的值,并且是线程安全的,因为这些变量都是每个线程本地存储的,即使访问它们的代码可能被另一个线程同时执行,依旧是线程安全的。
不可变量
对象一旦初始化以后就不能改变。这意味着只有只读数据被共享,这也实现了固有的线程安全性。可变(不是常量)操作可以通过为它们创建新对象,而不是修改现有对象的方式去实现。 Java,C#和 Python 中的字符串的实现就使用了这种方法。
线程同步
第一类方法都比较简单,通过代码改造就可以实现。但是如果遇到一定要进行线程中共享数据的情况,第一类方法就解决不了了。这时候就出现了第二类解决方案,利用线程同步的方法来解决线程安全问题。
线程同步理论
在多线程的程序中,多以共享数据作为线程之间传递数据的手段。由于一个进程所拥有的相当一部分虚拟内存地址都可以被该进程中所有线程共享,所以这些共享数据大多是以内存空间作为载体的。如果两个线程同时读取同一块共享内存但获取到的数据却不同,那么程序很容易出现一些 bug。
为了保证共享数据一致性,最简单并且最彻底的方法就是使该数据成为一个不变量。当然这种绝对的方式在大多数情况下都是不可行的。比如函数中会用到一个计数器,记录函数被调用了几次,这个计数器肯定就不能被设为常量。那这种必须是变量的情况下,还要保证共享数据的一致性,这就引出了临界区的概念。
临界区的出现就是为了使该区域只能被串行的访问或者执行。临界区可以是某个资源,也可以是某段代码。保证临界区最有效的方式就是利用线程同步机制。
先介绍2种共享数据同步的方法。
互斥量
在同一时刻,只允许一个线程处于临界区之内的约束称为互斥,每个线程在进入临界区之前,都必须先锁定某个对象,只有成功锁定对象的线程才能允许进入临界区,否则就会阻塞。这个对象称为互斥对象或者互斥量。
一般我们日常说的互斥锁就能达到这个目的。
互斥量可以有多个,它们所保护的临界区也可以有多个。先从简单的说起,一个互斥量和一个临界区。
一个互斥量和一个临界区
当线程1先进入临界区的时候,当前临界区处于未上锁的状态,于是它便先将临界区上锁。线程1获取到临界区里面的值。
这个时候线程2准备进入临界区,由于线程1把临界区上锁了,所以线程2进入临界区失败,线程2由就绪状态转成睡眠状态。线程1继续对临界区的共享数据进行写入操作。
当线程1完成所有的操作以后,线程1调用解锁操作。当临界区被解锁以后,会尝试唤醒正在睡眠的线程2。线程2被唤醒以后,由睡眠状态再次转换成就绪状态。线程2准备进入临界区,当临界区此处处于未上锁的状态,线程2便将临界区上锁。
经过 read、write 一系列操作以后,最终在离开临界区的时候会解锁。
线程在离开临界区的时候,一定要记得把对应的互斥量解锁。这样其他因临界区被上锁而导致睡眠的线程还有机会被唤醒。所以对同一个互斥变量的锁定和解锁必须成对的出现。既不可以对一个互斥变量进行重复的锁定,也不能对一个互斥变量进行多次的解锁。
如果对一个互斥变量锁定多次可能会导致临界区最终永远阻塞。可能有人会问了,对一个未锁定的互斥变成解锁多次会出现什么问题呢?
在 Go 1.8 之前,虽然对互斥变量解锁多次不会引起任何 goroutine 的阻塞,但是它可能引起一个运行时的恐慌。Go 1.8 之前的版本,是可以尝试恢复这个恐慌的,但是恢复以后,可能会导致一系列的问题,比如重复解锁操作的 goroutine 会永久的阻塞。所以 Go 1.8 版本以后此类运行时的恐慌就变成了不可恢复的了。所以对互斥变量反复解锁就会导致运行时操作,最终程序异常退出。
多个互斥量和一个临界区
在这种情况下,极容易产生线程死锁的情况。所以尽量不要让不同的互斥量所保护的临界区重叠。
举例,一个临界区中存在2个互斥量:互斥量 A 和互斥量 B。
线程1先锁定了互斥量 A ,接着线程2锁定了互斥量 B。当线程1在成功锁定互斥量 B 之前永远不会释放互斥量 A。同样,线程2在成功锁定互斥量 A 之前永远不会释放互斥量 B。那么这个时候线程1和线程2都因无法锁定自己需要锁定的互斥量,都由 ready 就绪状态转换为 sleep 睡眠状态。这是就产生了线程死锁了。
线程死锁的产生原因有以下几种:
- 1.系统资源竞争
- 2.进程推荐顺序非法
- 3.死锁必要条件(必要条件中任意一个不满足,死锁都不会发生)
(1). 互斥条件
(2). 不剥夺条件
(3). 请求和保持条件
(4). 循环等待条件
想避免线程死锁的情况发生有以下几种方法可以解决:
1.预防死锁
(1). 资源有序分配法(破坏环路等待条件)
(2). 资源原子分配法(破坏请求和保持条件)2.避免死锁
银行家算法3.检测死锁
死锁定理(资源分配图化简法),这种方法虽然可以检测,但是无法预防,检测出来了死锁还需要配合解除死锁的方法才行。
彻底解决死锁有以下几种方法:
1.剥夺资源
2.撤销进程
3.试锁定 — 回退
如果在执行一个代码块的时候,需要先后(顺序不定)锁定两个变量,那么在成功锁定其中一个互斥量之后应该使用试锁定的方法来锁定另外一个变量。如果试锁定第二个互斥量失败,就把已经锁定的第一个互斥量解锁,并重新对这两个互斥量进行锁定和试锁定。线程2在锁定互斥量 B 的时候,再试锁定互斥量 A,此时锁定失败,于是就把互斥量 B 也一起解锁。接着线程1会来锁定互斥量 A。此时也不会出现死锁的情况。
固定顺序锁定
这种方式就是让线程1和线程2都按照相同的顺序锁定互斥量,都按成功锁定互斥量1以后才能去锁定互斥量2 。这样就能保证在一个线程完全离开这些重叠的临界区之前,不会有其他同样需要锁定那些互斥量的线程进入到那里。
多个互斥量和多个临界区
多个临界区和多个互斥量的情况就要看是否会有冲突的区域,如果出现相互交集的冲突区域,后进临界区的线程就会进入睡眠状态,直到该临界区的线程完成任务以后,再被唤醒。
一般情况下,应该尽量少的使用互斥量。每个互斥量保护的临界区应该在合理范围内并尽量大。但是如果发现多个线程会频繁出入某个较大的临界区,并且它们之间经常存在访问冲突,那么就应该把这个较大的临界区划分的更小一点,并使用不同的互斥量保护起来。这样做的目的就是为了让等待进入同一个临界区的线程数变少,从而降低线程被阻塞的概率,并减少它们被迫进入睡眠状态的时间,这从一定程度上提高了程序的整体性能。
在说另外一个线程同步的方法之前,回答一下文章开头留下的一个疑问:可重入只是线程安全的充分不必要条件,并不是充要条件。这个反例在下面会讲到。
这个问题最关键的一点在于:mutex 是不可重入的。
举个例子:
在下面这段代码中,函数 increment_counter 是线程安全的,但不是可重入的。
1 |
|
上面的代码中,函数 increment_counter 可以在多个线程中被调用,因为有一个互斥锁 mutex 来同步对共享变量 counter 的访问。但是如果这个函数用在可重入的中断处理程序中,如果在 pthread_mutex_lock(&mutex) 和 pthread_mutex_unlock(&mutex) 之间产生另一个调用函数 increment_counter 的中断,则会第二次执行此函数,此时由于 mutex 已被 lock,函数会在 pthread_mutex_lock(&mutex) 处阻塞,并且由于 mutex 没有机会被 unlock,阻塞会永远持续下去。简言之,问题在于 pthread 的 mutex 是不可重入的。
解决办法是设定 PTHREAD_MUTEX_RECURSIVE 属性。然而对于给出的问题而言,专门使用一个 mutex 来保护一次简单的增量操作显然过于昂贵,因此 c++11 中的 原子变量 提供了一个可使此函数既线程安全又可重入(而且还更简洁)的替代方案:
1 |
|
在 Go 中,互斥量在标准库代码包 sync 中的 Mutex 结构体表示的。sync.Mutex 类型只有两个公开的指针方法,Lock 和 Unlock。前者用于锁定当前的互斥量,后者则用于对当前的互斥量进行解锁。
条件变量
在线程同步的方法中,还有一个可以与互斥量相提并论的同步方法,条件变量。
条件变量与互斥量不同,条件变量的作用并不是保证在同一时刻仅有一个线程访问某一个共享数据,而是在对应的共享数据的状态发生变化时,通知其他因此而被阻塞的线程。条件变量总是与互斥变量组合使用的。
这类问题其实很常见。先用生产者消费者的例子来举例。
如果不用条件变量,只用互斥量,来看看会发生什么后果。
生产者线程在完成添加操作之前,其他的生产者线程和消费者线程都无法进行操作。同一个商品也只能被一个消费者消费。
如果只用互斥量,可能会出现2个问题。
生产者线程获得了互斥量以后,却发现商品已满,无法再添加新的商品了。于是该线程就会一直等待。新的生产者也进入不了临界区,消费者也无法进入。这时候就死锁了。
消费者线程获得了互斥量以后,却发现商品是空的,无法消费了。这个时候该线程也是会一直等待。新的生产者和消费者也都无法进入。这时候同样也死锁了。
这就是只用互斥量无法解决的问题。在多个线程之间,急需一套同步的机制,能让这些线程都协作起来。
条件变量就是大家熟悉的 P - V 操作了。这块大家应该比较熟悉,所以简单的过一下。
P 操作就是 wait 操作,它的意思就是阻塞当前线程,直到收到该条件变量发来的通知。
V 操作就是 signal 操作,它的意思就是让该条件变量向至少一个正在等待它通知的线程发送通知,以表示某个共享数据的状态已经变化。
Broadcast 广播通知,它的意思就是让条件变量给正在等待它通知的所有线程发送通知,以表示某个共享数据的状态已经发生改变。
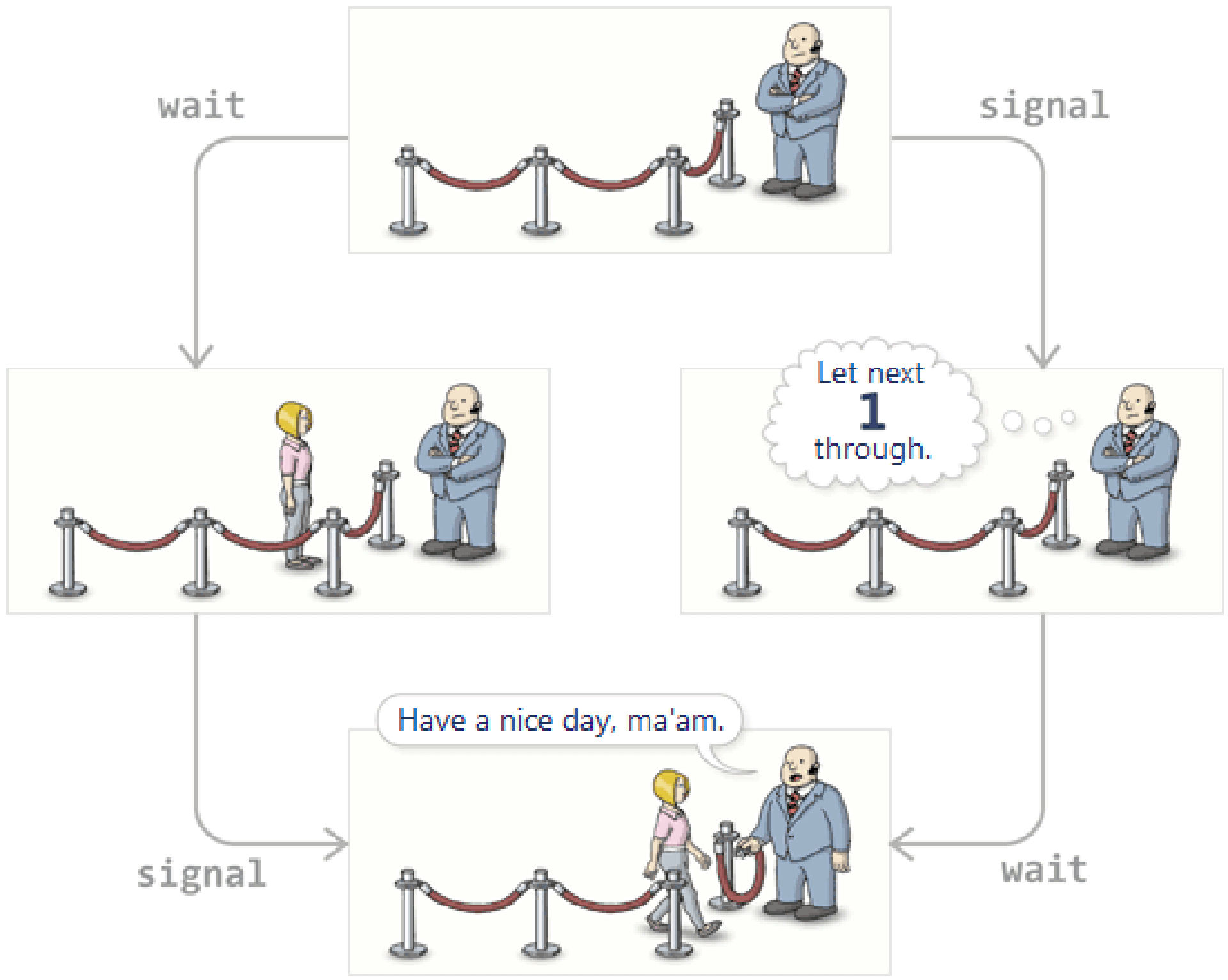
signal 可以操作多次,如果操作3次,就代表发了3次信号通知。P - V 操作设计美妙之处在于,P 操作的次数与 V 操作的次数是相同的。wait 多少次,signal 对应的有多少次。看上图,这个循环就是这么的奇妙。
生产者消费者问题
临界区只允许一个线程进入,当已经有一个线程了,再来一个线程,就会被 lock 住。当之前的线程离开以后,就会允许一个线程进入临界区。
1 | // 初始变量 |
虽然在生产者和消费者单个程序里面 P,V 并不是成对的,但是整个程序里面 P,V 还是成对的。
读者写者问题——读者优先,写者延迟
读者优先,写进程被延迟。只要有读者在读,后来的读者都可以随意进来读。
读者要先进入 rmutex ,查看 readcount,然后修改 readcout 的值,最后再去读数据。对于每个读进程都是写者,都要进去修改 readcount 的值,所以还要单独设置一个 rmutex 互斥访问。
初始变量:
1 | int readcount = 0; // 读者数量 |
读者线程:
1 | reader() |
写者线程:
1 | writer() |
读者写者问题——写者优先,读者延迟
有写者写,禁止后面的读者来读。在写者前的读者,读完就走。只要有写者在等待,禁止后来的读者进去读。
初始变量:
1 | int readcount = 0; // 读者数量 |
读者线程:
1 | reader() |
写者线程:
1 | writer() |
哲学家进餐问题
假设有五位哲学家围坐在一张圆形餐桌旁,做以下两件事情之一:吃饭,或者思考。吃东西的时候,他们就停止思考,思考的时候也停止吃东西。餐桌中间有一大碗意大利面,每两个哲学家之间有一只餐叉。因为用一只餐叉很难吃到意大利面,所以假设哲学家必须用两只餐叉吃东西。他们只能使用自己左右手边的那两只餐叉。哲学家就餐问题有时也用米饭和筷子而不是意大利面和餐叉来描述,因为很明显,吃米饭必须用两根筷子。
初始变量:
1 | semaphore chopstick[5] = {1,1,1,1,1}; // 初始化信号量 |
哲学家线程:
1 | Pi() |
综上所述,互斥量可以实现对临界区的保护,并会阻止竞态条件的发生。条件变量作为补充手段,可以让多方协作更加有效率。
在 Go 的标准库中,sync 包里面 sync.Cond 类型代表了条件变量。但是和互斥锁和读写锁不同的是,简单的声明无法创建出一个可用的条件变量,还需要用到 sync.NewCond 函数。
1 | func NewCond( l locker) *Cond |
*sync.Cond 类型的方法集合中有3个方法,即 Wait、Signal 和 Broadcast 。
简单的线程锁方案
实现线程安全的方案最简单的方法就是加锁了。
先看看 OC 中如何实现一个线程安全的字典吧。
在 Weex 的源码中,就实现了一套线程安全的字典。类名叫WXThreadSafeMutableDictionary。Go 用互斥量实现了一个简单的线程安全的 Map 。
既然要用到互斥量,那么就需要封装一个包含互斥量的 Map 。
1 | type MyMap struct { |
再简单的实现 Map 的基础方法。
1 | func builtinMapStore(k, v int) { |
实现思想比较简单,在每个操作前都加上 lock,在每个函数结束 defer 的时候都加上 unlock。
这种加锁的方式实现的线程安全的字典,优点是比较简单,缺点是性能不高。文章最后会进行几种实现方法的性能对比,用数字说话,就知道这种基于互斥量加锁方式实现的性能有多差了。
在语言原生就自带线程安全 Map 的语言中,它们的原生底层实现都不是通过单纯的加锁来实现线程安全的,比如 Java 的 ConcurrentHashMap,Go 1.9 新加的 sync.map。
现代线程安全的 Lock - Free 方案 CAS
在 Java 的 ConcurrentHashMap 底层实现中大量的利用了 volatile,final,CAS 等 Lock-Free 技术来减少锁竞争对于性能的影响。
在 Go 中也大量的使用了原子操作,CAS 是其中之一。比较并交换即 “Compare And Swap”,简称 CAS。
1 | func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool) |
CAS 会先判断参数 addr 指向的被操作值与参数 old 的值是否相等。如果相当,相应的函数才会用参数 new 代表的新值替换旧值。否则,替换操作就会被忽略。
这一点与互斥锁明显不同,CAS 总是假设被操作的值未曾改变,并一旦确认这个假设成立,就立即进行值的替换。而互斥锁的做法就更加谨慎,总是先假设会有并发的操作修改被操作的值,并需要使用锁将相关操作放入临界区中加以保护。可以说互斥锁的做法趋于悲观,CAS 的做法趋于乐观,类似乐观锁。
CAS 做法最大的优势在于可以不创建互斥量和临界区的情况下,完成并发安全的值替换操作。这样大大的减少了线程同步操作对程序性能的影响。当然 CAS 也有一些缺点,缺点下一章会提到。
接下来看看源码是如何实现的。以下以64位为例,32位类似。
1 | TEXT ·CompareAndSwapUintptr(SB),NOSPLIT,$0-25 |
上述实现最关键的一步就是 CMPXCHG。
Lock - Free 方案举例
NO Lock - Free 方案 ConcurrentMap
如果不用 Lock - Free 方案也不用简单的互斥量的方案,如何实现一个线程安全的字典呢?答案是利用分段锁的设计,只有在同一个分段内才存在竞态关系,不同的分段锁之间没有锁竞争。相比于对整个 Map 加锁的设计,分段锁大大的提高了高并发环境下的处理能力。
1 | type ConcurrentMap []*ConcurrentMapShared |
分段锁 Segment 存在一个并发度。并发度可以理解为程序运行时能够同时更新 ConccurentMap 且不产生锁竞争的最大线程数,实际上就是 ConcurrentMap 中的分段锁个数。即数组的长度。
1 | var SHARD_COUNT = 32 |
如果并发度设置的过小,会带来严重的锁竞争问题;如果并发度设置的过大,原本位于同一个 Segment 内的访问会扩散到不同的 Segment 中,CPU cache 命中率会下降,从而引起程序性能下降。
ConcurrentMap 的初始化就是对数组的初始化,并且初始化数组里面每个字典。
1 | func New() ConcurrentMap { |
ConcurrentMap 主要使用 Segment 来实现减小锁粒度,把 Map 分割成若干个 Segment,在 put 的时候需要加读写锁,get 时候只加读锁。
既然分段了,那么针对每个 key 对应哪一个段的逻辑就由一个哈希函数来定。
1 | func fnv32(key string) uint32 { |
上面这段哈希函数会根据每次传入的 string ,计算出不同的哈希值。
1 | func (m ConcurrentMap) GetShard(key string) *ConcurrentMapShared { |
根据哈希值对数组长度取余,取出 ConcurrentMap 中的 ConcurrentMapShared。在 ConcurrentMapShared 中存储对应这个段的 key - value。
1 | func (m ConcurrentMap) Set(key string, value interface{}) { |
上面这段就是 ConcurrentMap 的 set 操作。思路很清晰:先取出对应段内的 ConcurrentMapShared,然后再加读写锁锁定,写入 key - value,写入成功以后再释放读写锁。
1 | func (m ConcurrentMap) Get(key string) (interface{}, bool) { |
上面这段就是 ConcurrentMap 的 get 操作。思路也很清晰:先取出对应段内的 ConcurrentMapShared,然后再加读锁锁定,读取 key - value,读取成功以后再释放读锁。
这里和 set 操作的区别就在于只需要加读锁即可,不用加读写锁。
1 | func (m ConcurrentMap) Count() int { |
ConcurrentMap 的 Count 操作就是把 ConcurrentMap 数组的每一个分段元素里面的每一个元素都遍历一遍,计算出总数。
1 | func (m ConcurrentMap) Keys() []string { |
上述是返回 ConcurrentMap 中所有 key ,结果装在字符串数组中。
1 | type UpsertCb func(exist bool, valueInMap interface{}, newValue interface{}) interface{} |
上述代码是 Upsert 操作。如果已经存在了,就更新。如果是一个新元素,就用 UpsertCb 函数插入一个新的。思路也是先根据 string 找到对应的段,然后加读写锁。这里只能加读写锁,因为不管是 update 还是 insert 操作,都需要写入。读取 key 对应的 value 值,然后调用 UpsertCb 函数,把结果更新到 key 对应的 value 中。最后释放读写锁即可。
UpsertCb 函数在这里值得说明的是,这个函数是回调返回待插入到 map 中的新元素。这个函数当且仅当在读写锁被锁定的时候才会被调用,因此一定不允许再去尝试读取同一个 map 中的其他 key 值。因为这样会导致线程死锁。死锁的原因是 Go 中 sync.RWLock 是不可重入的。
完整的代码见concurrent_map.go
这种分段的方法虽然比单纯的加互斥量好很多,因为 Segment 把锁住的范围进一步的减少了,但是这个范围依旧比较大,还能再进一步的减少锁么?
还有一点就是并发量的设置,要合理,不能太大也不能太小。
Lock - Free 方案 sync.map
在 Go 1.9 的版本中默认就实现了一种线程安全的 Map,摒弃了 Segment(分段锁)的概念,而是启用了一种全新的方式实现,利用了 CAS 算法,即 Lock - Free 方案。
采用 Lock - Free 方案以后,能比上一个分案,分段锁更进一步缩小锁的范围。性能大大提升。
接下来就让我们来看看如何用 CAS 实现一个线程安全的高性能 Map 。
官方是 sync.map 有如下的描述:
这个 Map 是线程安全的,读取,插入,删除也都保持着常数级的时间复杂度。多个 goroutines 协程同时调用 Map 方法也是线程安全的。该 Map 的零值是有效的,并且零值是一个空的 Map 。线程安全的 Map 在第一次使用之后,不允许被拷贝。
这里解释一下为何不能被拷贝。因为对结构体的复制不但会生成该值的副本,还会生成其中字段的副本。如此一来,本应施加于此的并发线程安全保护也就失效了。
作为源值赋给别的变量,作为参数值传入函数,作为结果值从函数返回,作为元素值通过通道传递等都会造成值的复制。正确的做法是用指向该类型的指针类型的变量。
Go 1.9 中 sync.map 的数据结构如下:
1 | type Map struct { |
在这个 Map 中,包含一个互斥量 mu,一个原子值 read,一个非线程安全的字典 map,这个字典的 key 是 interface{} 类型,value 是 *entry 类型。最后还有一个 int 类型的计数器。
先来说说原子值。atomic.Value 这个类型有两个公开的指针方法,Load 和 Store 。Load 方法用于原子地的读取原子值实例中存储的值,它会返回一个 interface{} 类型的结果,并且不接受任何参数。Store 方法用于原子地在原子值实例中存储一个值,它接受一个 interface{} 类型的参数而没有任何结果。在未曾通过 Store 方法向原子值实例存储值之前,它的 Load 方法总会返回 nil。
在这个线程安全的字典中,Load 和 Store 的都是一个 readOnly 的数据结构。
1 | // readOnly 是一个不可变的结构体,原子性的存储在 Map.read 中 |
readOnly 中存储了一个非线程安全的字典,这个字典和上面 dirty map 存储的类型完全一致。key 是 interface{} 类型,value 是 *entry 类型。
1 | // entry 是一个插槽,与 map 中特定的 key 相对应 |
p 指针指向 *interface{} 类型,里面存储的是 entry 的地址。如果 p = = nil,代表 entry 被删除了,并且 m.dirty = = nil。如果 p = = expunged,代表 entry 被删除了,并且 m.dirty != nil ,那么 entry 从 m.dirty 中丢失了。
除去以上两种情况外,entry 都是有效的,并且被记录在 m.read.m[key] 中,如果 m.dirty!= nil,entry 被存储在 m.dirty[key] 中。
一个 entry 可以通过原子替换操作成 nil 来删除它。当 m.dirty 在下一次被创建,entry 会被 expunged 指针原子性的替换为 nil,m.dirty[key] 不对应任何 value。只要 p != expunged,那么一个 entry 就可以通过原子替换操作更新关联的 value。如果 p = = expunged,那么一个 entry 想要通过原子替换操作更新关联的 value,只能在首次设置 m.dirty[key] = e 以后才能更新 value。这样做是为了能在 dirty map 中查找到它。
所以从上面分析可以看出,read 中的 key 是 readOnly 的(key 的集合不会变,删除也只是打一个标记),value 的操作全都可以原子完成,所以这个结构不用加锁。dirty 是一个 read 的拷贝,加锁的操作都在这里,如增加元素、删除元素等(dirty上执行删除操作就是真的删除)具体操作见下面分析。
再看看线程安全的 sync.map 的一些操作。
1 | func (m *Map) Load(key interface{}) (value interface{}, ok bool) { |
上述代码是 Load 操作。返回的是入参 key 对应的 value 值。如果 value 不存在就返回 nil。dirty map 中会保存一些 read map 里面不存在的 key,那么就要读取出 dirty map 里面 key 对应的 value。注意读取的时候需要加互斥锁,因为 dirty map 是非线程安全的。
1 | func (m *Map) missLocked() { |
上面这段代码是记录 misses 次数的。只有当 misses 个数大于 dirty map 的长度的时候,会把 dirty map 存储到 read map 中。并且把 dirty 置空,misses 次数也清零。
在看 Store 操作之前,先说一个 expunged 变量。
1 | // expunged 是一个指向任意类型的指针,用来标记从 dirty map 中删除的 entry |
expunged 变量是一个指针,用来标记从 dirty map 中删除的 entry。
1 | func (m *Map) Store(key, value interface{}) { |
Store 优先从 read map 里面去读取 key ,然后存储它的 value。如果 entry 是被标记为从 dirty map 中删除过的,那么还需要重新存储回 dirty map中。
如果 read map 里面没有相应的 key,就去 dirty map 里面去读取。dirty map 就直接存储对应的 value。
最后如何 read map 和 dirty map 都没有这个 key 值,这就意味着该 key 是第一次被加入到 dirty map 中。在 dirty map 中存储这个 key 以及对应的 value。
1 | // 当 entry 没有被删除的情况下去存储一个 value。 |
tryStore 函数的实现和 CAS 原理差不多,它会反复的循环判断 entry 是否被标记成了 expunged,如果 entry 经过 CAS 操作成功的替换成了 i,那么就返回 true,反之如果被标记成了 expunged,就返回 false。
1 | // unexpungeLocked 函数确保了 entry 没有被标记成已被清除。 |
如果 entry 的 unexpungeLocked 返回为 true,那么就说明 entry 已经被标记成了 expunged,那么它就会经过 CAS 操作把它置为 nil。
再来看看删除操作的实现。
1 | func (m *Map) Delete(key interface{}) { |
delete 操作的实现比较简单,如果 read map 中存在 key,就可以直接删除,如果不存在 key 并且 dirty map 中有这个 key,那么就要删除 dirty map 中的这个 key。操作 dirty map 的时候记得先加上锁进行保护。
1 | func (e *entry) delete() (hadValue bool) { |
删除 entry 具体的实现如上。这个操作里面都是原子性操作。循环判断 entry 是否为 nil 或者已经被标记成了 expunged,如果是这种情况就返回 false,代表删除失败。否则就 CAS 操作,将 entry 的 p 指针置为 nil,并返回 true,代表删除成功。
至此,关于 Go 1.9 中自带的线程安全的 sync.map 的实现就分析完了。官方的实现里面基本没有用到锁,互斥量的 lock 也是基于 CAS的。read map 也是原子性的。所以比之前加锁的实现版本性能有所提升。
如果 read 中的一个 key 被删除了,即被打了 expunged 标记,然后如果再添加相同的 key,不需要操作 dirty,直接恢复回来就可以了。
如果 dirty 没有任何数据的时候,删除了 read 中的 key,同样也是加上 expunged 标记,再添加另外一个不同的 key,dirtyLocked() 函数会把 read 中所有已经有的 key-value 全部都拷贝到 dirty 中保存,并再追加上 read 中最后添加上的和之前删掉不同的 key。
这就等同于:
当 dirty 不存在的时候,read 就是全部 map 的数据。
当 dirty 存在的时候,dirty 才是正确的 map 数据。
从 sync.map 的实现中我们可以看出,它的思想重点在读取是无锁的。字典大部分操作也都是读取,多个读者之间是可以无锁的。当 read 中的数据 miss 到一定程度的时候,(有点命中缓存的意思),就会考虑直接把 dirty 替换成 read,整个一个赋值替换就可以了。但是在 dirty 重新生成新的时候,或者说第一个 dirty 生成的时候,还是需要遍历整个 read,这里会消耗很多性能,那官方的这个 sync.map 的性能究竟是怎么样的呢?
总结
纵观 Java ConcurrentHashmap 一路的变化:
JDK 6,7 中的 ConcurrentHashmap 主要使用 Segment 来实现减小锁粒度,把 HashMap 分割成若干个 Segment,在 put 的时候需要锁住 Segment,get 时候不加锁,使用 volatile 来保证可见性,当要统计全局时(比如size),首先会尝试多次计算 modcount 来确定,这几次尝试中,是否有其他线程进行了修改操作,如果没有,则直接返回 size。如果有,则需要依次锁住所有的 Segment 来计算。
JDK 7 中 ConcurrentHashmap 中,当长度过长碰撞会很频繁,链表的增改删查操作都会消耗很长的时间,影响性能,所以 JDK8 中完全重写了concurrentHashmap,代码量从原来的1000多行变成了 6000多行,实现上也和原来的分段式存储有很大的区别。
JDK 8 的 ConcurrentHashmap 主要设计上的变化有以下几点:
- 不采用 Segment 而采用 node,锁住 node 来实现减小锁粒度。
- 设计了 MOVED 状态 当 Resize 的中过程中线程2还在 put 数据,线程2会帮助 resize。
- 使用3个 CAS 操作来确保 node 的一些操作的原子性,这种方式代替了锁。
- sizeCtl 的不同值来代表不同含义,起到了控制的作用。
可见 Go 1.9 一上来第一个版本就直接摒弃了 Segment 的做法,采取了 CAS 这种 Lock - Free 的方案提高性能。但是它并没有对整个字典进行类似 Java 的 Node 的设计。但是整个 sync.map 在 ns/op ,B/op,allocs/op 这三个性能指标上是普通原生非线程安全 Map 的三倍!