在写分页相关的业务逻辑时都会有一个统计行数的需求,此时一般会使用count函数。但是随着数据量的增长,count的执行越来越慢。
下面用真实环境中的一个例子来引入对count函数的分析。
环境说明:MySQL版本为 8.0.29
首先我们创建两张测试表
1
2
3
4
5
6
7
| CREATE TABLE `t1` (
`id` int NOT NULL AUTO_INCREMENT,
`name` char(20) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '',
`age` int NOT NULL DEFAULT '0',
`del_state` tinyint NOT NULL DEFAULT '1',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4194230 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
|
1
2
3
4
5
6
7
8
9
| CREATE TABLE `t2` (
`id` int NOT NULL AUTO_INCREMENT,
`name` char(20) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '',
`age` int NOT NULL DEFAULT '0',
`del_state` tinyint NOT NULL DEFAULT '1',
PRIMARY KEY (`id`),
KEY `t2_del_state_index` (`del_state`),
KEY `t2_name_index` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=4128706 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
|
t1和t2的数据是一样的,t1表和t2表的区别是t2表多了 del_state 和 name 字段的索引
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| mysql> select count(*) from t1;
+----------+
| count(*) |
+----------+
| 4063232 |
+----------+
1 row in set (0.68 sec)
mysql> select count(*) from t2;
+----------+
| count(*) |
+----------+
| 4063232 |
+----------+
1 row in set (0.80 sec)
|
问题引入
下面两个sql,可以看到t2的查询使用到了del_state索引,但是它的查询时长远远大于t1的查询。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| mysql> select count(*) from t1 where del_state=1 and age > 25;
+----------+
| count(*) |
+----------+
| 1572864 |
+----------+
1 row in set (0.95 sec)
mysql> select count(*) from t2 where del_state=1 and age > 25;
+----------+
| count(*) |
+----------+
| 1572864 |
+----------+
1 row in set (8.46 sec)
mysql> desc select count(*) from t1 where del_state=1 and age > 25;
+----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 4049850 | 3.33 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
mysql> desc select count(*) from t2 where del_state=1 and age > 25;
+----+-------------+-------+------------+------+--------------------+--------------------+---------+-------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+--------------------+--------------------+---------+-------+---------+----------+-------------+
| 1 | SIMPLE | t2 | NULL | ref | t2_del_state_index | t2_del_state_index | 4 | const | 2024925 | 33.33 | Using where |
+----+-------------+-------+------------+------+--------------------+--------------------+---------+-------+---------+----------+-------------+
1 row in set, 1 warning (0.01 sec)
|
背景介绍
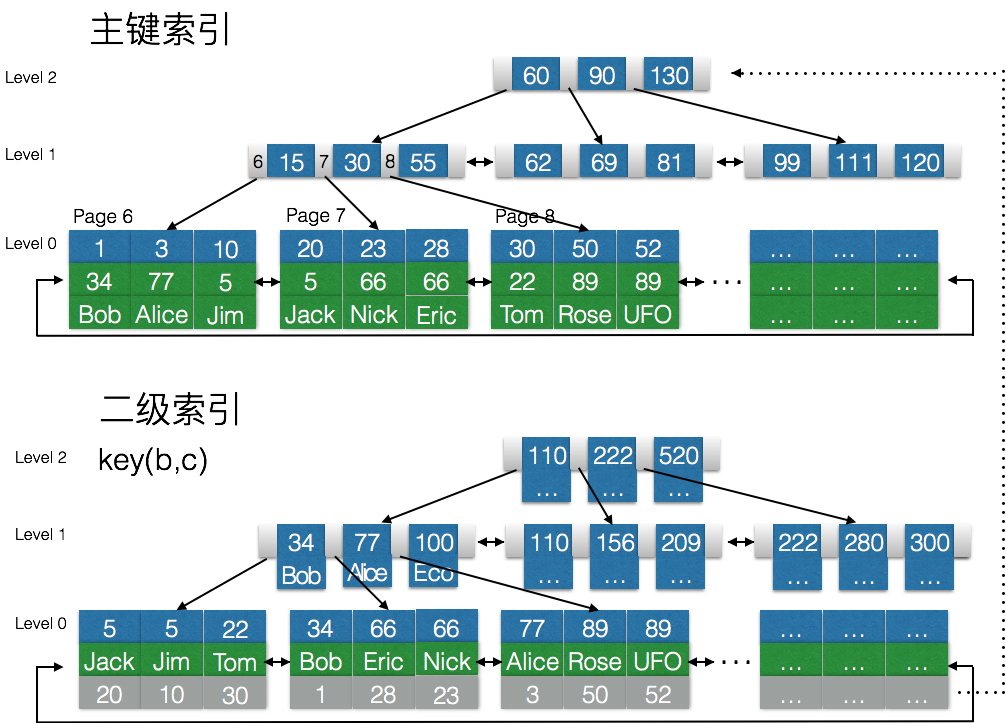
聚簇索引
- 聚簇索引的叶子节点就是数据节点,而非聚簇索引的叶子节点仍然是索引节点,只不过有指向对应数据块的指针。
- 在InnoDB中,主键索引就是聚簇索引,聚簇索引的每个叶子节点中包含着主键值和剩余的列
下面这张图,大致就是这个意思:上边的是主键索引(聚集索引),下边的是普通索引(非聚集索引)
回表
如果是通过非主键索引进行查询,select所要获取的字段不能通过非主键索引获取到,需要通过非主键索引获取到的主键,从聚集索引再次查询一遍,获取到所要查询的记录,这个查询的过程就是回表
server层和存储引擎的交互
以下面的查询为例:
1
| select * from t2 where name='aaa' and age > 22;
|
假设数据库优化器认为通过扫描二级索引name成本更小,查询的过程为:
- 通过二级索引
name对应的B+树,从B+树根部一层一层向下定位,快速找到name='aaa'区间的第一条记录,然后根据这条索引记录对应的聚簇索引的指针,进行回表操作,找到完整的聚簇索引记录,然后返回给server层。(也就是说得到一条二级索引记录后立即去回表,而不是把所有的二级索引记录都拿到后统一去回表)
- server层在接收到存储引擎层返回的记录之后,接着就要判断其余的WHERE条件是否成立(
age>22),如果成立的话,就直接发送给客户端。
此处将记录发送给客户端其实是发送到本地的网络缓冲区,等缓冲区满了才真正发送网络包到客户端。
- 接着server层向存储引擎层要求继续读刚才那条记录的下一条记录。
- 继续回表,继续判断where条件
- … 一直循环上述过程,直到找不到下一条记录,则向server层报告查询完毕。
一般情况下server层和存储引擎层是以记录为单位进行交互的。
count函数
COUNT是一个汇总函数(聚集函数),它接收1个表达式作为参数:
expr表达式,可以是字段,常量,’*’
例如:
1
| select count(id) from t2;
|
t2表的所有记录中,id列不为NULL的行数是多少。
1
| select count(1) from t2;
|
t2表的所有记录中,1这个表达式不为NULL的行数是多少。很显然,1这个表达式永远不是NULL,所以上述语句其实就是统计t2表里有多少条记录。
1
| select count(*) from t2;
|
这个语句就是直接统计t2表有多少条记录。
总结:COUNT函数的参数可以是任意表达式,该函数用于统计在符合搜索条件的记录中,指定的表达式不为NULL的行数有多少。
问题分析
经过上面关于查询中server和存储引擎的交互,以及回表的概念,可以知道,在执行
select count(*) from t2 where del_state=1 and age > 25时,先使用del_state索引查到指定范围的记录,由于age没有索引, 所以需要逐条回表去查询聚簇索引,判断age字段。
这样查询的效率明显低于全表扫描。
思考与扩展
通过上述的分析,当建立二级索引时,需要保证索引有优秀的过滤性,能够筛选出指定的少量数据
另外在建立索引后,查询时还需要减少回表的次数,这是可以考虑使用联合索引
在上面t2表的查询中,可以当设置(del_state,age)的联合索引,就不会产生回表,而是在联合索引上判断age的大小。
这里(del_state,age)的索引只是举例,具体索引还需要结合业务场景和表结构来创建。