Live data migration
出于业务升级,数据库更换选型,数据库大版本升级等业务或技术的各种原因。可能会有将数据从数据源A迁移至数据源B的需求。为确保业务稳定,迁移过程需要平稳、安全,并且保证双边数据一致性。
静态数据
对于稳定不变的只读性数据,分为简单的两步即可:
- 将存量数据直接从数据源A导致入数据源B
- 切换业务路由至数据源B
上面两步均不存在不一致情况。
动态数据
对于同时读写的动态数据,一般分成三步:
- 增量迁移,将新增的数据直接写入数据源B
- 存量迁移,将存量数据迁移至数据源B
- 切换业务路由至数据源B
每步可以通过不同的技术手段达到目的,但临界或异常时可能会出现数据分叉的情况,需要额外的技术手段消除。
双读切写模式
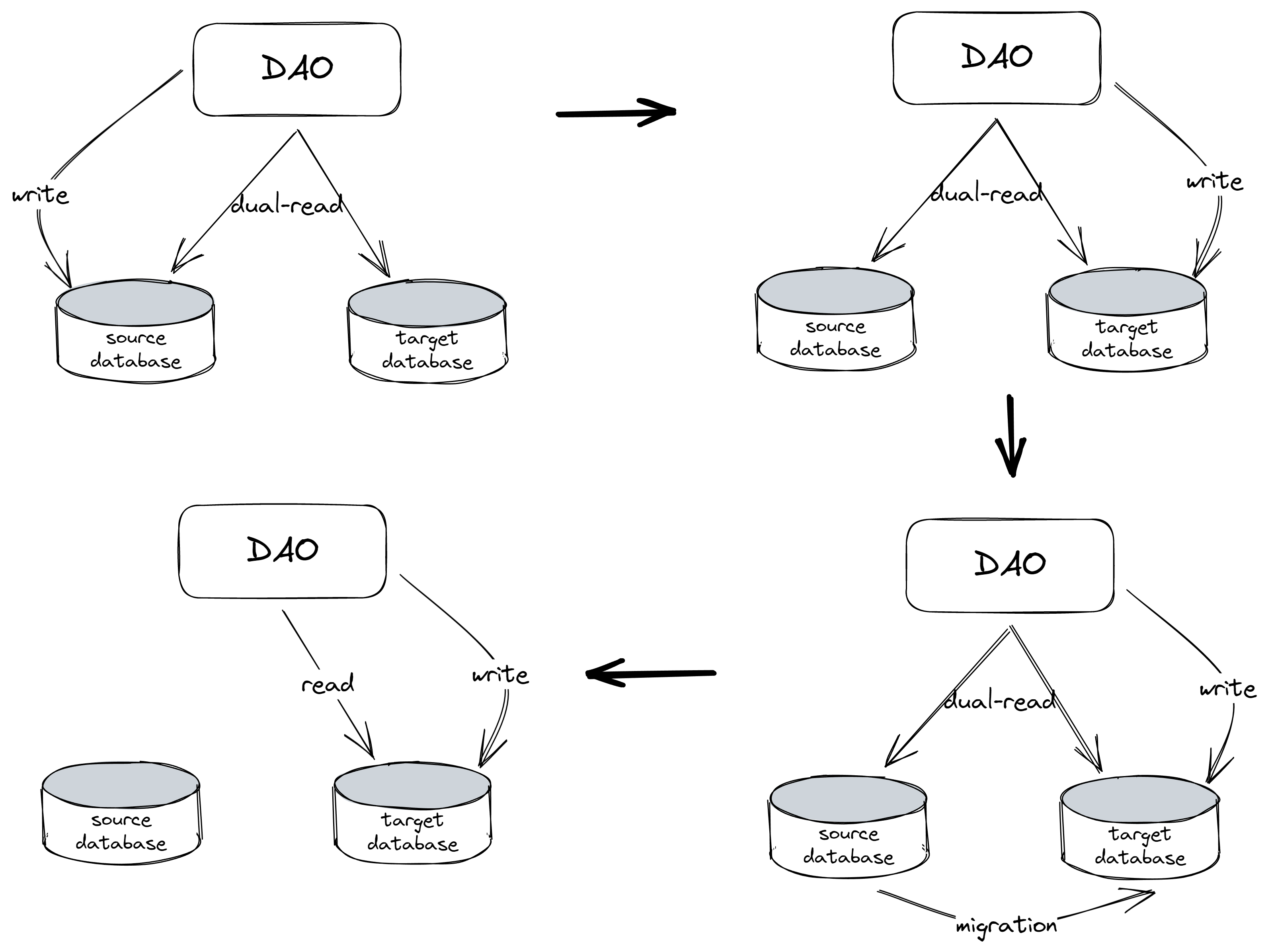
读一致性
通过双读比较数据的版本,以较高者为准。
切写的原子性
由于分布式机器中存在通信延迟的情况,上图第二步切换写路由的动作无法在多个DAO机器中原子性完成,会出现部分DAO机器已切写至target db,但有部分DAO机器仍会写向source db的临界情况。
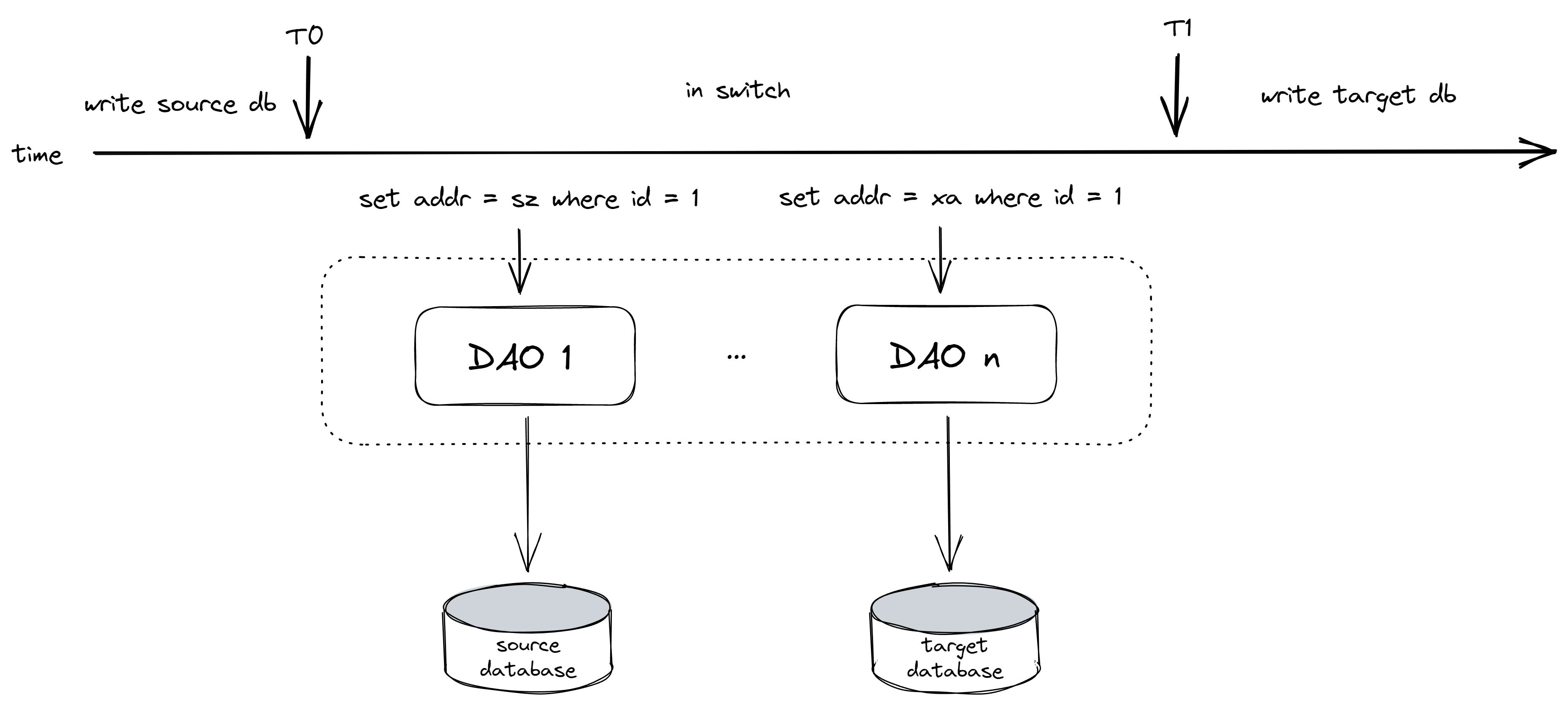
在T0~T1期间出现并发请求,导致对于同一个id的记录,在两个数据库中版本一致但内部不一致,且都对上层业务返回了成功,出现了数据分叉。
对于并发情况较多或对一致性要求较高的场景,切写不一致的解决方法:
在T0~T1期间,只读不写,按经验T1-T0>DAO超时时间 * 4
按用户或商户维度分批择时切写,避免全量不可写
对于并发情况较少或容忍少量非一致性的场景,可以开放T0~T1期间的写请求,采用事后处理的策略:
双读时发现不一致性情况,采用信任某一数据源策略,或直接报错并告警,人工干预处理
准实时对账两个数据库,发现数据不一致性后告警,人工干预处理
同步双写模式
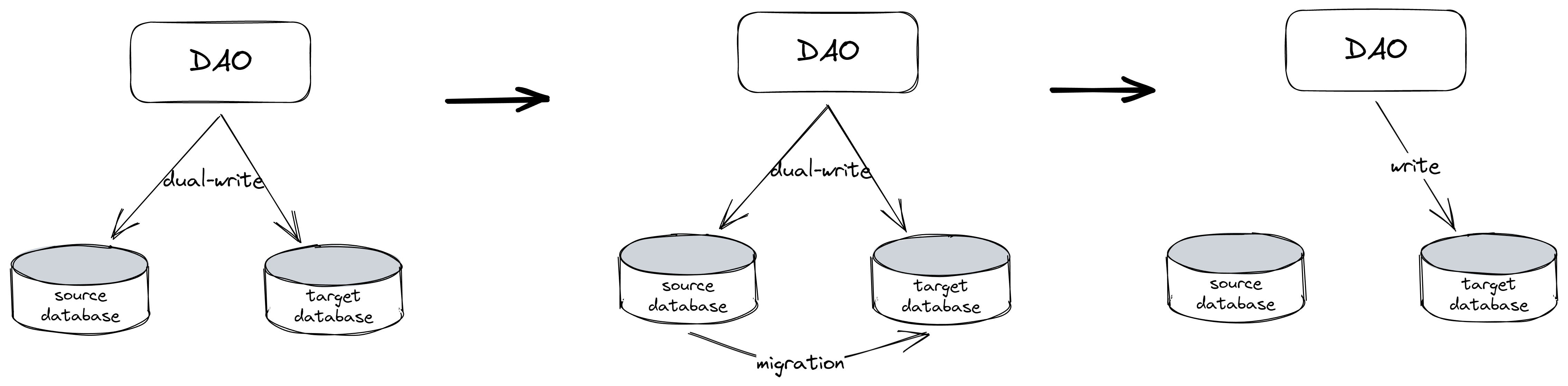
同步双写一般不是一个原子操作,也就会出现source db写成功,target db写失败的异常情况,这会引发一些值得探讨的问题:
应向业务返回成功还是失败?
先假设返回成功,考虑以下场景:
- 假设有一条 Create 请求: X (key=hanbo, addr=sz, version=0),写source db成功,写target db失败。此时返回成功,此条数据X已经不一致,即source db有数据X,而target db无数据X。
- 上图第一步双写完成,进入第二步迁移存量数据,会将数据X迁移至target db。数据X达成一致,符合预期。
- 迁移完成后,有另一条 Create 请求:Y (key=bobo, addr=xa, version=0),写source db成功,写target db失败。此时返回成功,但迁移已经完成,数据源B不会再有机会迁移数据Y,等于这条数据就丢失了,不符合预期。
因此此种异常不应返回成功,应向业务返回失败。
如何保证读一致性?即读时应以哪个数据源为准?
假设读以source db为准,上述异常时,向业务返回了失败。此时业务查询又返回了数据,前后不一致,不符合预期。
又对于存量数据,由于只存在于source db,读必须以source db为准。
因此应将读分为两类:
- 双写数据的读应以target db为准
- 存量数据应以source db为准
哪些写请求应该双写?
写请求可分类为:
Create 请求
Update 请求
双写数据(Create双写产生)的Update
存量数据的Update
Create 请求是新增数据,应 双写。
双写数据的Update请求,由于双写数据的读以数据源B为准,所以必须双写。
存量数据的Update请求,先假设双写,考虑以下场景:
- 已有存量数据X(key=tencent, addr=sz, version=1),即数据源A有数据X,数据源B无数据X
- 此时有Update请求 set addr=sh where key=tencent 。双写时写数据源A成功,写数据源B失败,向业务返回失败。此时数据源A有X(key=tencent, addr=sh, version=2),数据源B无X
- 业务查询数据X(预期应该是addr=sz),若读数据源A会返回addr=sh,前后逻辑不一致,不符合预期;若读数据源B会返回空,不符合预期
因此存量数据的Update请求不应双写。
如何处理这种异常导致的不一致?
这种异常一般不影响业务的读写一致性,可以不用处理。
但对于迁移的回滚产生不一致影响,考虑以下场景:
- 假设有一条 Create 请求: X (key=tencent, addr=sz, version=0),写数据源A成功,写数据源B失败。向业务返回失败,此条数据X已经不一致,即数据源A有数据X,而数据源B无数据X。
- 由于某种故障或其他原因,需要回滚迁移,即结束迁移流程,业务读写都路由至数据源A。
- 务查询数据X(预期应该是返回空),但却返回(key=tencent, addr=sz, version=0),不符合预期
这种回滚导致的前后不一致,对于资金转账类场景完全不可接受(比如转账失败,最后却多一条转账成功的记录),只能一条路走到黑。
存量数据迁移的一致性
存量数据的写请求路由至数据源A,存量数据迁移时写向数据源B,若两者同时出现,会出现数据不一致情况,考虑以下场景:
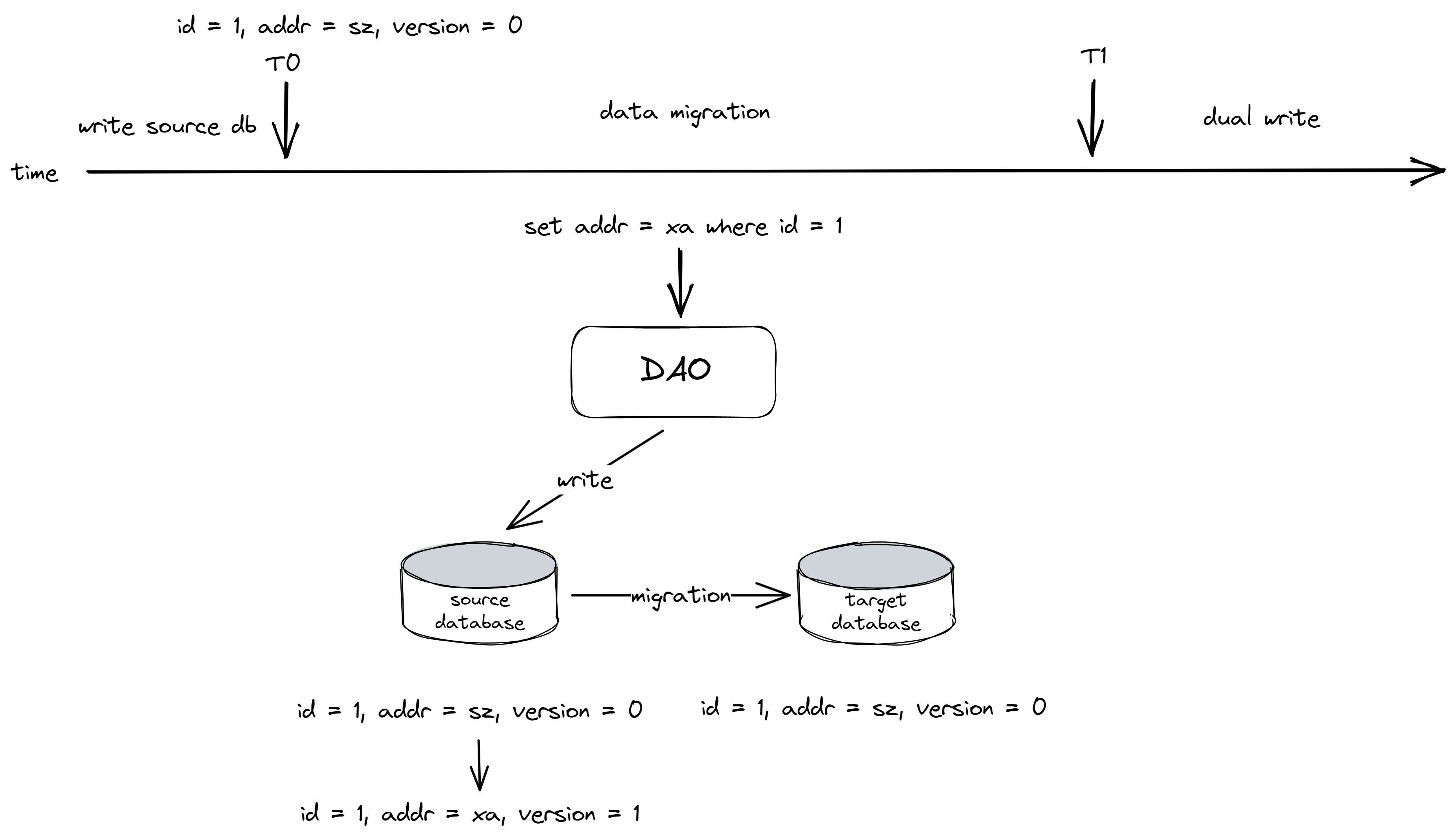
在T0~T1期间,若有写请求修改了数据源A,则会导致数据源A比数据源B更新。在迁移完成后,数据成为双写数据,读以数据源B为准,会彻底丢失了这次业务的成功更新。
针对迁移中的不一致解决办法:
- 在T0~T1的迁移过程中,只读不写
- 按用户、商户或其他维度分批逐渐迁移,避免全量不可写