Persistent Storage
持久存储是在关闭该设备电源后保留数据的任何数据存储设备。它有时也被称为非易失性存储。
Types of persistent storage
在容器化中,持久存储是指存储卷(通常与数据库等有状态应用程序相关联),这些卷在单个容器的生命周期之后仍然可用。持久性存储卷可以与临时存储卷形成对比,后者与容器一起生存和死亡,并与无状态应用相关联。
从用户角度看,存储就是一块盘或者一个目录,用户不关心盘或者目录如何实现,用户要求非常简单,就是稳定,性能好。为了能够提供稳定可靠的存储产品,各个厂家推出了各种各样的存储技术和概念。为了能够让大家有一个整体认识,本文先介绍存储中的这些概念。
从存储介质角度,存储介质分为机械硬盘和固态硬盘(SSD)。机械硬盘泛指采用磁头寻址的磁盘设备,包括SATA硬盘和SAS硬盘。由于采用磁头寻址,机械硬盘性能一般,随机IOPS一般在200左右,顺序带宽在150MB/s左右。固态硬盘是指采用Flash/DRAM芯片+控制器组成的设备,根据协议的不同,又分为SATA SSD,SAS SSD,PCIe SSD和NVMe SSD。
从产品定义角度,存储分为本地存储(DAS),网络存储(NAS),存储局域网(SAN)和软件定义存储(SDS)四大类。
- DAS就是本地盘,直接插到服务器上
- NAS是指提供NFS协议的NAS设备,通常采用磁盘阵列+协议网关的方式
- SAN跟NAS类似,提供SCSI/iSCSI协议,后端是磁盘阵列
- SDS是一种泛指,包括分布式NAS(并行文件系统),ServerSAN等
从应用场景角度,存储分为文件存储(Posix/MPI),块存储(iSCSI/Qemu)和对象存储(S3/Swift)三大类。
块存储
就好比硬盘一样, 直接挂在到主机, 一般用于主机的直接存储空间和数据库应用(如: mysql)的存储。
块存储(DAS/SAN)通常应用在某些专有的系统中,这类应用要求很高的随机读写性能和高可靠性,上面搭载的通常是Oracle/DB2这种传统数据库,连接通常是以FC光纤(8Gb/16Gb)为主,走光纤协议。如果要求稍低一些,也会出现基于千兆/万兆以太网的连接方式,MySQL这种数据库就可能会使用IP SAN,走iSCSI协议。
通常使用块存储的都是系统而非用户,并发访问不会很多,经常出现一套存储只服务一个应用系统,例如如交易系统,计费系统。典型行业如金融,制造,能源,电信等。
文件系统
文件存储(NAS)相对来说就更能兼顾多个应用和更多用户访问,同时提供方便的数据共享手段。
在PC时代,数据共享也大多是用文件的形式,比如常见的的FTP服务,NFS服务,Samba共享这些都是属于典型的文件存储。几十个用户甚至上百用户的文件存储共享访问都可以用NAS存储加以解决。
在中小企业市场,一两台NAS存储设备就能支撑整个IT部门了。CRM系统,SCM系统,OA系统,邮件系统都可以使用NAS存储统统搞定。甚至在公有云发展的早几年,用户规模没有上来时,云存储的底层硬件也有用几套NAS存储设备就解决的,甚至云主机的镜像也有放在NAS存储上的例子。
文件存储的广泛兼容性和易用性,是这类存储的突出特点。
但是从性能上来看,相对SAN就要低一些。NAS存储基本上是以太网访问模式,普通千兆网,走NFS/CIFS协议。
对象存储
前面说到的块存储和文件存储,基本上都还是在专有的局域网络内部使用,而对象存储的优势场景却是互联网或者公网,主要解决海量数据,海量并发访问的需求。
基于互联网的应用才是对象存储的主要适配(当然这个条件同样适用于云计算,基于互联网的应用最容易迁移到云上),基本所有成熟的公有云都提供了对象存储产品,不管是国内还是国外。
对象存储常见的适配应用如网盘、媒体娱乐,医疗PACS,气象,归档等数据量超大而又相对“冷数据”和非在线处理的应用类型。
这类应用单个数据大,总量也大,适合对象存储海量和易扩展的特点。
网盘类应用也差不多,数据总量很大,另外还有并发访问量也大,支持10万级用户访问这种需求就值得单列一个项目了。归档类应用只是数据量大的冷数据,并发访问的需求倒是不太突出。
另外基于移动端的一些新兴应用也是适合的,智能手机和移动互联网普及的情况下,所谓UGD(用户产生的数据,手机的照片视频)总量和用户数都是很大挑战。毕竟直接使用HTTP get/put就能直接实现数据存取,对移动应用来说还是有一定吸引力的。
对象存储的访问通常是在互联网,走HTTP协议,性能方面,单独看一个连接的是不高的(还要解决掉线断点续传之类的可靠性问题),主要强大的地方是支持的并发数量,聚合起来的性能带宽就非常可观了。
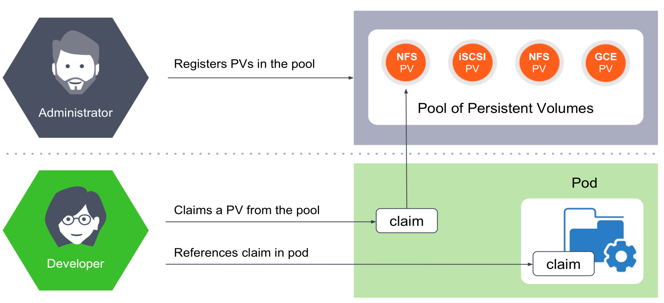
Kubernetes是如何给存储定义和分类呢?Kubernetes中跟存储相关的概念有PersistentVolume (PV)和PersistentVolumeClaim(PVC),PV又分为静态PV和动态PV。
PV 是群集中的资源,其生命周期独立于使用 PV 的任何单个 Pod 。这是主机上存储持久数据的物理卷。持久卷在群集中提供存储资源,即使循环使用它们的 Pod 也允许存储资源保留。PersistentVolumes 可以静态或动态配置,并且可以通过定义性能、大小和访问模式等属性来自定义它们以供使用。
PVC 是对资源的请求,这些资源充当对资源的声明检查。PVC 是对平台创建持久卷并通过 PVC 将 PV 附加到 Pod 的请求。
PV又分为静态PV和动态PV。静态PV方式如下:
动态PV需要引入StorageClass的概念,使用方式如下:
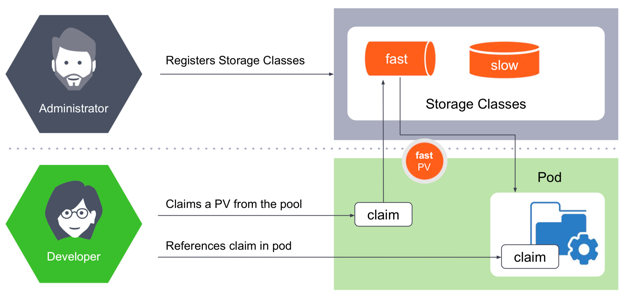
社区列举出PersistentVolume的in-tree Plugin,Kubernetes通过访问模式给存储分为三大类,RWO/ROX/RWX。这种分类将原有的存储概念混淆,其中包含存储协议,存储开源产品,存储商业产品,公有云存储产品等等。
- 块存储通常只支持RWO,比如AWSElasticBlockStore,AzureDisk,有些产品能做到支持ROX,比如GCEPersistentDisk,RBD,ScaleIO等
- 文件存储(分布式文件系统)支持RWO/ROX/RWX三种模式,比如CephFS,GlusterFS和AzureFile
- 对象存储不需要PV/PVC来做资源抽象,应用可以直接访问和使用
相关开源组件
市面上的存储产品种类繁多,但是对于容器场景,主要集中在4种方案:分布式文件存储,分布式块存储,Local-Disk和传统NAS。
基本特性对比
| 存储系统 | Ceph | GlusterFS | Swift | HDFS | FastDFS | Ambry |
|---|---|---|---|---|---|---|
| 开发语言 | C++ | C | Python | Java | C | Java |
| 开源协议 | LGPL | GPL3 | Apache | Apache | GPL3 | Apache |
| Start数 | 4667/2501 | 1626/636 | 1759/915 | 7558/4,786 | 3011/915 | 1073/206 |
| 存储方式 | 对象/文件/块 | 文件/块 | 对象 | 文件 | 文件/块 | 对象 |
| 在线扩容 | 支持 | 支持 | 支持 | 支持 | 支持 | 支持 |
| 冗余备份 | 支持 | 支持 | 支持 | 支持 | 支持 | 支持 |
| 单点故障 | 不存在 | 不存在 | 不存在 | 存在 | 不存在 | 不存在 |
| 易用性 | 一般 | 简单 | 一般 | 一般 | 简单 | 简单 |
| 跨集群 | 不支持 | 支持 | 不支持 | 不支持 | 不支持 | 不支持 |
| 适用场景 | 大中小文件 | 大中小文件 | 大中小文件 | 大中文件 | 中小文件 | 大中小文件 |
Ceph
Ceph是个开源的分布式存储,底层是RADOS,这是个标准的对象存储。以RADOS为基础,Ceph 能够提供文件,块和对象三种存储服务,旨在提供一个扩展性强大、性能优越且无单点故障的分布式存储系统。
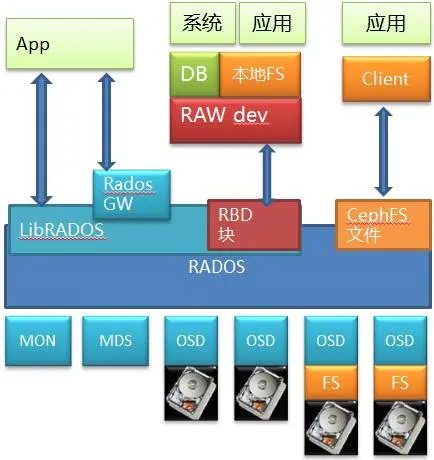
在Ceph存储中,包含了几个重要的核心组件,分别是Ceph OSD、Ceph Monitor和Ceph MDS。一个Ceph的存储集群至少需要一个Ceph Monitor和至少两个Ceph的OSD。运行Ceph文件系统的客户端时,Ceph的元数据服务器(MDS)是必不可少的。
其中通过RBD提供出来的块存储是比较有价值的地方,毕竟因为市面上开源的分布式块存储少见。
当然它也通过CephFS模块和相应的私有Client提供了文件服务,这也是很多人认为Ceph是个文件系统的原因。
另外它自己原生的对象存储可以通过RadosGW存储网关模块向外提供对象存储服务,并且和对象存储的事实标准Amazon S3以及Swift兼容。所以能看出来这其实是个大一统解决方案,啥都齐全。
RADOS也是个标准对象存储,里面也有MDS的元数据管理和OSD的数据存储,而OSD本身是可以基于一个本地文件系统的,比如XFS/EXT4/Brtfs。
数据访问路径,如果看Ceph的文件接口,自底层向上,经过了硬盘(块)->文件->对象->文件的路径;如果看RBD的块存储服务,则经过了硬盘(块)->文件->对象->块,也可能是硬盘(块)->对象->块的路径;再看看对象接口(虽然用的不多),则是经过了硬盘(块)->文件->对象或者硬盘(块)->对象的路径。
GlusterFS
GlusterFS是Scale-Out存储解决方案Gluster的核心,它是一个开源的分布式文件系统,具有强大的横向扩展能力,通过扩展能够支持数PB存储容量和处理数千客户端。GlusterFS借助TCP/IP或InfiniBand RDMA网络将物理分布的存储资源聚集在一起,使用单一全局命名空间来管理数据。GlusterFS基于可堆叠的用户空间设计,可为各种不同的数据负载提供优异的性能。
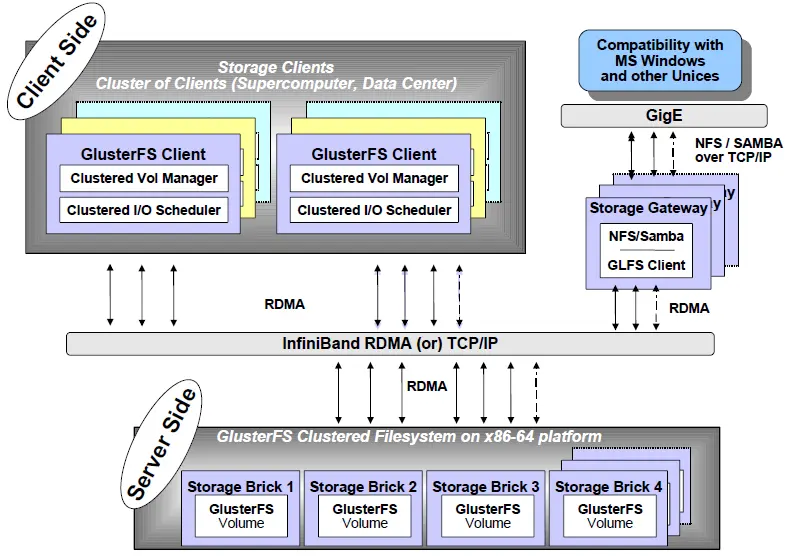
它主要由存储服务器(Brick Server)、客户端以及NFS/Samba存储网关组成。不难发现,GlusterFS架构中没有元数据服务器组件,这是其最大的设计这点,对于提升整个系统的性能、可靠性和稳定性都有着决定性的意义。GlusterFS支持TCP/IP和InfiniBand RDMA高速网络互联,客户端可通过原生Glusterfs协议访问数据,其他没有运行GlusterFS客户端的终端可通过NFS/CIFS标准协议通过存储网关访问数据。
GlusterFS是一个具有高扩展性、高性能、高可用性、可横向扩展的弹性分布式文件系统,在架构设计上非常有特点,比如无元数据服务器设计、堆栈式架构等。然而,存储应用问题是很复杂的,GlusterFS也不可能满足所有的存储需求,设计实现上也一定有考虑不足之处,下面我们作简要分析。
1.无元数据服务器 vs 元数据服务器
无元数据服务器设计的好处是没有单点故障和性能瓶颈问题,可提高系统扩展性、性能、可靠性和稳定性。对于海量小文件应用,这种设计能够有效解决元数据的难点问题。
它的负面影响是,数据一致问题更加复杂,文件目录遍历操作效率低下,缺乏全局监控管理功能。同时也导致客户端承担了更多的职能,比如文件定位、名字空间缓存、逻辑卷视图维护等等,这些都增加了客户端的负载,占用相当的CPU和内存。
2. 用户空间 vs 内核空间
用户空间实现起来相对要简单许多,对开发者技能要求较低,运行相对安全。用户空间效率低,数据需要多次与内核空间交换,另外GlusterFS借助FUSE来实现标准文件系统接口,性能上又有所损耗。
内核空间实现可以获得很高的数据吞吐量,缺点是实现和调试非常困难,程序出错经常会导致系统崩溃,安全性低。纵向扩展上,内核空间要优于用户空间,GlusterFS有横向扩展能力来弥补。
3. 堆栈式 vs 非堆栈式
GlusterFS堆栈式设计思想源自GNU/Hurd微内核操作系统,具有很强的系统扩展能力,系统设计实现复杂性降低很多,基本功能模块的堆栈式组合就可以实现强大的功能。查看GlusterFS卷配置文件我们可以发现,translator功能树通常深达10层以上,一层一层进行调用,效率可见一斑。
非堆栈式设计可看成类似Linux的单一内核设计,系统调用通过中断实现,非常高效。后者的问题是系统核心臃肿,实现和扩展复杂,出现问题调试困难。
4. 原始存储格式 vs 私有存储格式
GlusterFS使用原始格式存储文件或数据分片,可以直接使用各种标准的工具进行访问,数据互操作性好,迁移和数据管理非常方便。然而,数据安全成了问题,因为数据是以平凡的方式保存的,接触数据的人可以直接复制和查看。这对很多应用显然是不能接受的,比如云存储系统,用户特别关心数据安全,这也是影响公有云存储发展的一个重要原因。
私有存储格式可以保证数据的安全性,即使泄露也是不可知的。GlusterFS要实现自己的私有格式,在设计实现和数据管理上相对复杂一些,也会对性能产生一定影响。
5. 大文件 vs 小文件
弹性哈希算法和Stripe数据分布策略,移除了元数据依赖,优化了数据分布,提高数据访问并行性,能够大幅提高大文件存储的性能。
对于小文件,无元数据服务设计解决了元数据的问题。
但GlusterFS并没有在I/O方面作优化,在存储服务器底层文件系统上仍然是大量小文件,本地文件系统元数据访问是一个瓶颈,数据分布和并行性也无法充分发挥作用。
因此,GlusterFS适合存储大文件,小文件性能较差,还存在很大优化空间。
6. 可用性 vs 存储利用率
GlusterFS使用复制技术来提供数据高可用性,复制数量没有限制,自动修复功能基于复制来实现。
可用性与存储利用率是一个矛盾体,可用性高存储利用率就低,反之亦然。
采用复制技术,存储利用率为1/复制数,镜像是50%,三路复制则只有33%。
其实,可以有方法来同时提高可用性和存储利用率,比如RAID5的利用率是(n-1)/n,RAID6是(n-2)/n,而纠删码技术可以提供更高的存储利用率。但是,鱼和熊掌不可得兼,它们都会对性能产生较大影响。
Swift
Swift 是OpenStack开源云计算项目的子项目之一,被称为对象存储,提供了强大的扩展性、冗余和持久性。 构筑在比较便宜的标准硬件存储基础设施之上,无需采用 RAID(磁盘冗余阵列),通过在软件层面引入一致性散列技术和数据冗余性,牺牲一定程度的数据一致性来达到高可用性和可伸缩性,支持多租户模式、容器和对象读写操作,适合解决互联网的应用场景下非结构化数据存储问题。
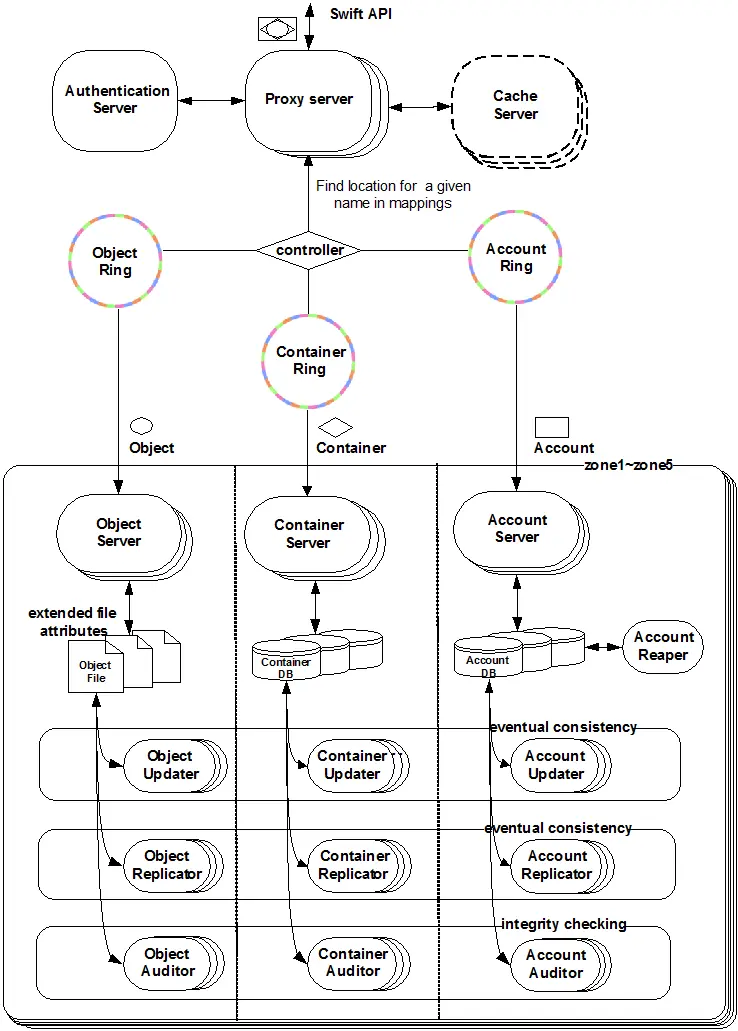
- 代理服务(Proxy Server):对外提供对象服务 API,会根据环的信息来查找服务地址并转发用户请求至相应的账户、容器或者对象服务;由于采用无状态的 REST 请求协议,可以进行横向扩展来均衡负载。
- 认证服务(Authentication Server):验证访问用户的身份信息,并获得一个对象访问令牌(Token),在一定的时间内会一直有效;验证访问令牌的有效性并缓存下来直至过期时间。
- 缓存服务(Cache Server):缓存的内容包括对象服务令牌,账户和容器的存在信息,但不会缓存对象本身的数据;缓存服务可采用 Memcached 集群,Swift 会使用一致性散列算法来分配缓存地址。
- 账户服务(Account Server):提供账户元数据和统计信息,并维护所含容器列表的服务,每个账户的信息被存储在一个 SQLite 数据库中。
- 容器服务(Container Server):提供容器元数据和统计信息,并维护所含对象列表的服务,每个容器的信息也存储在一个 SQLite 数据库中。
- 对象服务(Object Server):提供对象元数据和内容服务,每个对象的内容会以文件的形式存储在文件系统中,元数据会作为文件属性来存储,建议采用支持扩展属性的 XFS 文件系统。
- 复制服务(Replicator):会检测本地分区副本和远程副本是否一致,具体是通过对比散列文件和高级水印来完成,发现不一致时会采用推式(Push)更新远程副本,例如对象复制服务会使用远程文件拷贝工具 rsync 来同步;另外一个任务是确保被标记删除的对象从文件系统中移除。
- 更新服务(Updater):当对象由于高负载的原因而无法立即更新时,任务将会被序列化到在本地文件系统中进行排队,以便服务恢复后进行异步更新;例如成功创建对象后容器服务器没有及时更新对象列表,这个时候容器的更新操作就会进入排队中,更新服务会在系统恢复正常后扫描队列并进行相应的更新处理。
- 审计服务(Auditor):检查对象,容器和账户的完整性,如果发现比特级的错误,文件将被隔离,并复制其他的副本以覆盖本地损坏的副本;其他类型的错误会被记录到日志中。
- 账户清理服务(Account Reaper):移除被标记为删除的账户,删除其所包含的所有容器和对象。
HDFS
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。
HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。
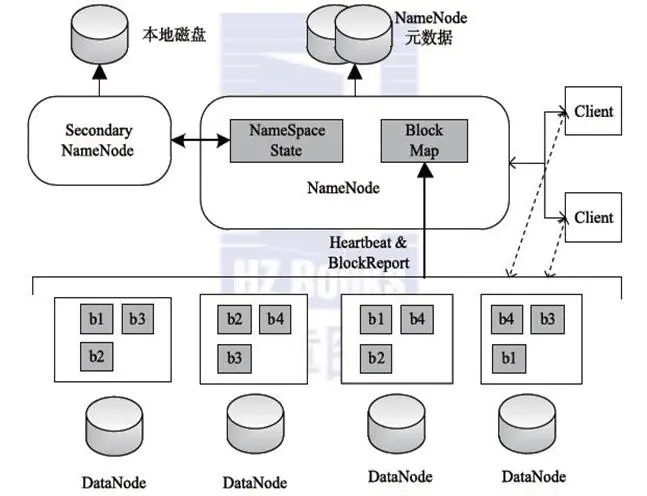
HDFS 采用Master/Slave的架构来存储数据,这种架构主要由四个部分组成,分别为HDFS Client、NameNode、DataNode和Secondary NameNode。
- Client:客户端
- 文件切分。文件上传 HDFS 的时候,Client 将文件切分成一个一个的Block,然后进行存储。
- 与 NameNode 交互,获取文件的位置信息。
- 与 DataNode 交互,读取或者写入数据。
- 提供一些命令来管理 HDFS,比如启动或者关闭HDFS。
- 可以通过一些命令来访问 HDFS。
- NameNode:master,它是一个主管、管理者。
- 管理 HDFS 的名称空间
- 管理数据块(Block)映射信息
- 配置副本策略
- 处理客户端读写请求。
- DataNode:Slave。NameNode 下达命令,DataNode 执行实际的操作。
- 存储实际的数据块。
- 执行数据块的读/写操作。
- Secondary NameNode:并非 NameNode 的热备。当NameNode挂掉的时候,它并不能马上替换 NameNode 并提供服务。
- 辅助 NameNode,分担其工作量。
- 定期合并 fsimage和fsedits,并推送给NameNode。
- 在紧急情况下,可辅助恢复 NameNode。
FastDFS
FastDFS 是一个开源的高性能分布式文件系统(DFS)。 它的主要功能包括:文件存储,文件同步和文件访问,以及高容量和负载平衡。主要解决了海量数据存储问题,特别适合以中小文件(建议范围:4KB < file_size < 500MB)为载体的在线服务。
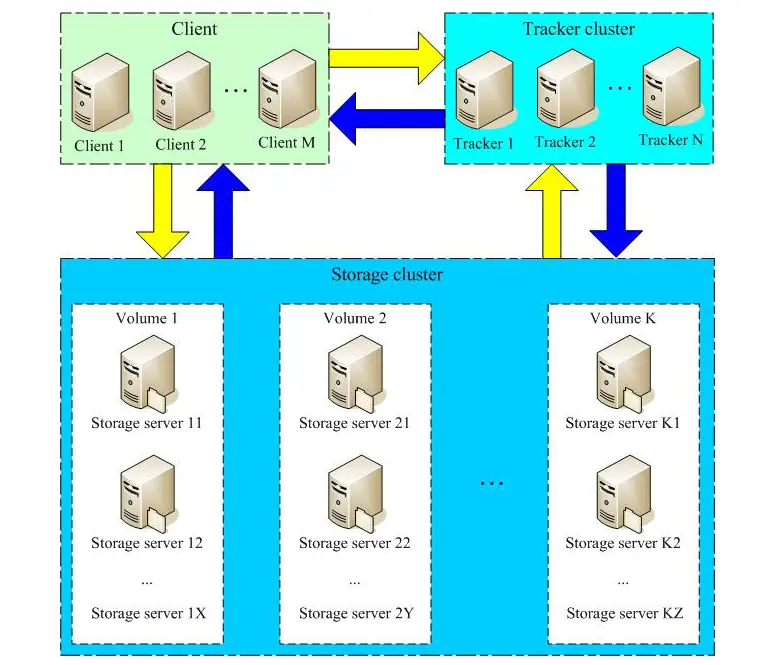
FastDFS 系统有三个角色:跟踪服务器(Tracker Server)、存储服务器(Storage Server)和客户端(Client)。
- Tracker Server:跟踪服务器,主要做调度工作,起到均衡的作用;负责管理所有的 storage server和 group,每个 storage 在启动后会连接 Tracker,告知自己所属 group 等信息,并保持周期性心跳。
- Storage Server:存储服务器,主要提供容量和备份服务;以 group 为单位,每个 group 内可以有多台 storage server,数据互为备份。
- Client:客户端,上传下载数据的服务器,也就是我们自己的项目所部署在的服务器。
为了支持大容量,存储节点(服务器)采用了分卷(或分组)的组织方式。存储系统由一个或多个卷组成,卷与卷之间的文件是相互独立的,所有卷的文件容量累加就是整个存储系统中的文件容量。一个卷可以由一台或多台存储服务器组成,一个卷下的存储服务器中的文件都是相同的,卷中的多台存储服务器起到了冗余备份和负载均衡的作用。
在卷中增加服务器时,同步已有的文件由系统自动完成,同步完成后,系统自动将新增服务器切换到线上提供服务。当存储空间不足或即将耗尽时,可以动态添加卷。只需要增加一台或多台服务器,并将它们配置为一个新的卷,这样就扩大了存储系统的容量。
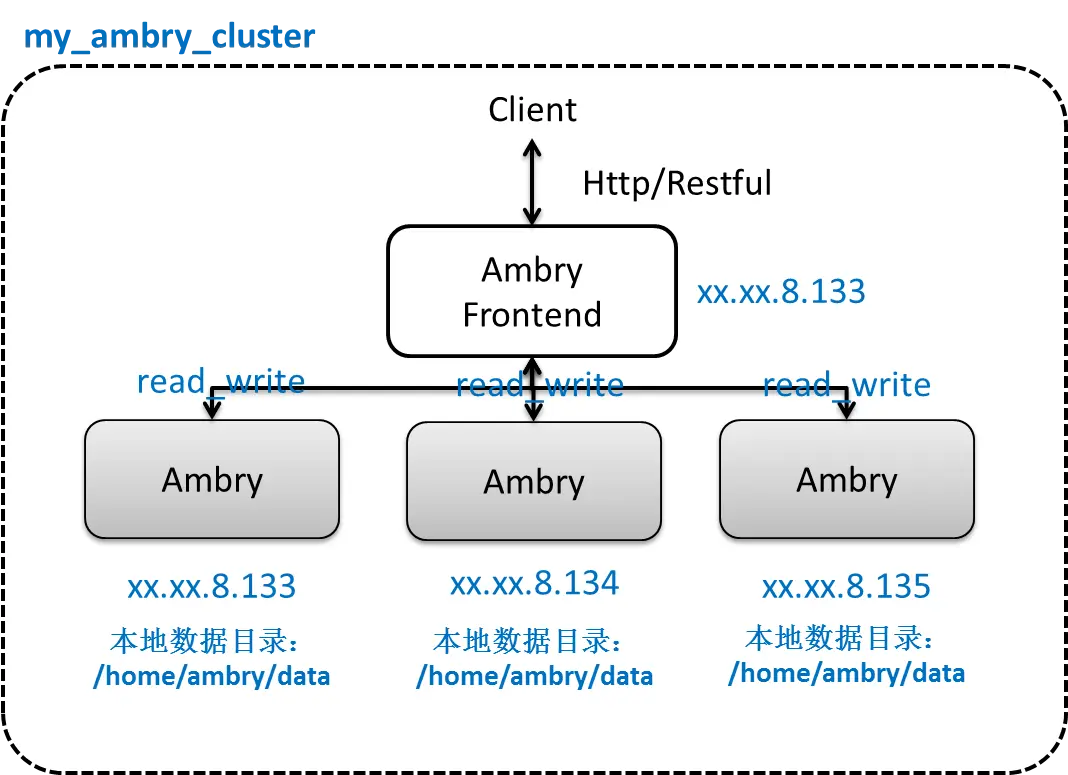
Ambry
Ambry是一个分布式不可变高可用对象存储系统,并且可容易扩展。 Ambry适用于存储从几KB到几GB的多媒体对象,并能保证高吞吐量以及低延迟。他也能实现从客户端到存储层端到端的直接通信,反之亦可。系统可以跨机房多活热部署,并且能提供非常廉价的存储。
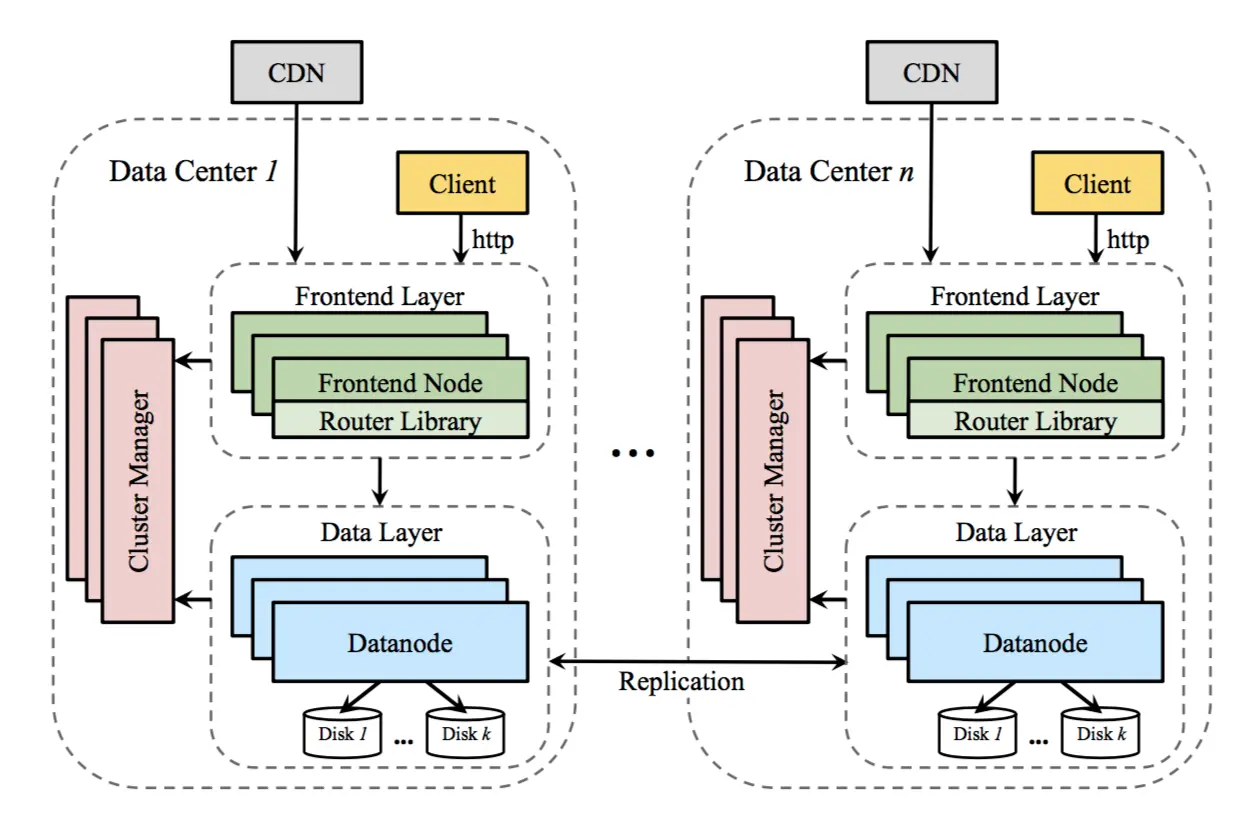
Ambry包含负责保存和检索数据的数据节点(data node),前端节点(Frontend node)将请求经过预处理发送到后端数据节点,并且集群管理者(Cluster manager)管理并协调数据节点上的数据。
数据节点之间互相复制数据,并且可以跨机房复制,并需要保证写之后读的一致性。前端提供HTTP API,包括POST,GET和DELETE对象。
同样的,这个路由库可以直接被客户端调用以提升性能。在LinkedIn,这些前端节点扮演着CDN的角色。
Ambry是一个偏向于处理的存储。这意味着当一个对象放入Ambry时,这个对象的ID被返回。这简化了系统设计并促使系统去中心化。客户端可以通过这个ID访问对应对象,这也意味着Ambry内的对象是不可变的。基于Ambry建立一个键值对访问并且支持对象可变的系统非常繁琐。
设计工作原理:
- 高可用以及水平可扩展;
- 低操作与运维开销;
- 低MTTR;
- 跨机房多活;
- 对于大小对象操作高效;
- 节约成本。
简单部署设计图:
Q&A
很多公司都想自己开发一套对象存储环境,为什么要选择厂家开发的对象存储呢?
Ceph并不是开源对象存储最好的选择,Ceph是个统一存储,有分布式块,文件,对象三种存储接口,比较全,这是它比较受关注的原因。单独来看底层的对象存储Rados,在开发者社区中口碑并不是很好,坑很多。
如果公司想自研,得有相当层次的开发团队,对大规模并行系统,存储底层,网络,操作系统都有点经验的,并且后续有Devops的思想准备,时间周期也不会太短,还要处理社区版本迭代和你自选分支的冲突或者渐行渐远的问题。
如果是选择厂商的SDS方案,如果是基于Ceph做的(国内不少厂商),其实这个阶段成熟与否还不好说,毕竟这项目社区里参与者很多,时间也不长,所谓成熟也就是有一部分坑能填上吧。前面说的社区版本迭代跟不跟的问题也还是一样存在的。
如果是纯看对象存储,Swift是个更好的选择,这也是OpenStack最早的两个项目之一,比较成熟,开发文档也很多,坑没有这么多,阿里在几年前就投入团队用C语言改写该项目,侧面也说明对该项目架构设计的认同。
HDFS文件系统和OpenStack swift对象存储有何不同?
- HDFS使用了中央系统来维护文件元数据(Namenode,名称节点),而在Swift中,元数据呈分布式,跨集群复制。使用一种中央元数据系统对HDFS来说无异于单一故障点,因而扩展到规模非常大的环境显得更困难。
- Swift在设计时考虑到了多租户架构,而HDFS没有多租户架构这个概念。
- HDFS针对更庞大的文件作了优化(这是处理数据时通常会出现的情况),Swift被设计成了可以存储任何大小的文件。
- 在HDFS中,文件写入一次,而且每次只能有一个文件写入;而在Swift中,文件可以写入多次;在并发操作环境下,以最近一次操作为准。
- HDFS用Java来编写,而Swift用Python来编写。
- 另外,HDFS被设计成了可以存储数量中等的大文件,以支持数据处理,而Swift被设计成了一种比较通用的存储解决方案,能够可靠地存储数量非常多的大小不一的文件。
- HDFS被设计成可以使用Hadoop,跨存储环境里面的对象实现MapReduce处理。而Openstack的使用者公司来说,他们想使用的是Swift里面的处理,而非MapReduce。
Q:你好,我们公司采用GlusterFS存储,挂载三块盘,现在遇到高并发写小文件(4KB)吞吐量上不去(5MB/S),请问有什么比较好的监控工具或方法么?谢谢!
A:GlusterFS本身对小文件就很不友好,GlusterFS是针对备份场景设计的,不建议用在小文件场景,如果可以的话,要么程序做优化进行小文件合并,要么选用高性能的分布式文件存储,建议看看Lustre或者YRCloudFile。Q:我们用的是Ceph分布式存储,目前有一个场景是客户视频存储,而对于持续的写入小文件存在丢帧的现象,经过我们系统级别和底层文件系统调优,加上Ceph参数的设置,勉强性能得改善,但是数据量上来性能会如何也不得而知道了(经过客户裸盘测试,前面用软RAID方式性能还是可以)请问在这方面你有什么建议么?谢谢!我们客户是在特殊的场景下,属于特定机型,而且是5400的sata盘!rbd块存储!还有一个现象就是磁盘利用率不均,这也是影响性能的一个人原因,即便我们在调pg数,也会有这个问题。在额外请教一个问题,bcache可以用内存做缓存么?FlushCache相比,这两个哪个会更好一点?
A:您用的是CephFS还是rbdc因为Ceph在性能上缺失做的还不够,有很多队列,导致延迟很不稳定,这个时候,只能忍了,不过还是建议用Bcache做一层缓存,可以有效缓解性能问题。Crush算法虽然比一致性hash要好很多,但是因为没有元数据,还是很难控制磁盘热点问题。FlushCache已经没有人维护了,Bcache还有团队在维护,所以如果自己没有能力,就选用Bcache。Q:我看您推荐分布式文件存储,文件系统能满足数据库应用的需求吗?块存储会不会好一些?
A:首先,我推荐的是高性能分布式文件系统。数据库一般对延迟都比较敏感,普通的万兆网络+HDD肯定不行,需要采用SSD,一般能将延迟稳定在毫秒以内,通常能够满足要求。如果对延迟有特别要求,可以采用NVMe + RoCE的方案,即使在大压力下,延迟也能稳定在300微秒以内。Q:请问为什么说块存储不支持RWX?RWX就是指多个节点同时挂载同一块块设备并同时读写吗?很多FC存储都可以做到。
A:传统的SAN要支持RWX,需要ALUA机制,而且这是块级别的多读写,如果要再加上文件系统,是没办法做到的,这需要分布式文件系统来做文件元数据信息同步。Q:传统SAN支持对同一数据块的并行读写,很多AA阵列都不是用ALUA的,而是多条路径同时有IO,当然要用到多路径软件。相反用ALUA的不是AA阵列。
A:AA阵列解决的是高可用问题,对同一个lun的并发读写,需要trunk级的锁去保证数据一致性,性能不好。Q:很多传统商业存储,包括块存储,也都做了CSI相关的插件,是不是如果在容器里跑一些性能要求高的业务,这些商业的块存储比文件存储合适?
A:生产环境中,我强烈建议选用商业存储。至于块存储还是文件存储,要看您的业务场景。首选是商业的文件存储。Q:请问现在的Kubernetes环境下,海量小文件RWX场景,有什么相对比较好的开源分布式存储解决方案么?
A:开源的分布式文件存储项目中,没有能解决海量小文件的,我在文中已经将主流开源文件系统都分析了一遍,在设计之初,都是针对备份场景或者HPC领域。Q:请问,为什么说Ceph性能不好,有依据吗?
A:直接用数据说话,我们用NVMe + Ceph + Bluestore测试出来的,延迟在毫秒级以上,而且很不稳定,我们用YRCloudFile + NVMe + RoCE,延迟能50微秒左右,差了几十倍。Q:Lustre没接触过,性能好吗,和Ceph有对比过吗?
A:网上有很多Lustre的性能指标,在同样的配置下,性能绝对要比Ceph好,不过Lustre全部都是内核态的,容器场景没办法用,而且按照部署以及运维难度非常大。Lustre在超算用的比较广泛。Q:Lustre只能靠本地磁盘阵列来保证数据冗余么?
A:Lustre本身不提供冗余机制,都是靠本地阵列的,不过EC好像已经在开发计划中了。Q:(对于小公司)如果不选用商业存储,那么推荐哪款开源实现作为生产存储(可靠,高性能)。我们之前试了NFS发现速度不稳定?
A:国内还是有很多创业公司,也不贵的。存储不像其他项目,存储经不起折腾,一定要用稳定可靠的,Ceph/GlusterFS做了这么久,大家在采购的时候,还是会依托于某家商业公司来做,自己生产环境用开源项目,风险太大了。
reference
Kubernetes Storage Explained - from in-tree plugin to CSI - Digi Hunch