Redis
Redis是一款内存高速缓存数据库。Redis全称为:Remote Dictionary Server(远程数据服务),使用C语言编写,Redis是一个key-value存储系统(键值存储系统),支持丰富的数据类型,如:String、list、set、zset、hash。
Redis是一种支持key-value等多种数据结构的存储系统。可用于缓存,事件发布或订阅,高速队列等场景。支持网络,提供字符串,哈希,列表,队列,集合结构直接存取,基于内存,可持久化。
为什么要使用Redis
一个产品的使用场景肯定是需要根据产品的特性,先列举一下Redis的特点:
- 读写性能优异
- Redis能读的速度是110000次/s,写的速度是81000次/s
- 数据类型丰富
- Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子性
- Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。
- 丰富的特性
- Redis支持 publish/subscribe, 通知, key 过期等特性。
- 持久化
- Redis支持RDB, AOF等持久化方式
- 发布订阅
- Redis支持发布/订阅模式
- 分布式
- Redis Cluster
下面是官方的bench-mark根据如下条件获得的性能测试(读的速度是110000次/s,写的速度是81000次/s)
- 测试完成了50个并发执行100000个请求。
- 设置和获取的值是一个256字节字符串。
- Linux box是运行Linux 2.6,这是X3320 Xeon 2.5 ghz。
- 文本执行使用loopback接口(127.0.0.1)。
Redis的使用场景
redis应用场景总结redis平时我们用到的地方蛮多的,下面就了解的应用场景做个总结:
热点数据的缓存
缓存是Redis最常见的应用场景,之所有这么使用,主要是因为Redis读写性能优异。而且逐渐有取代memcached,成为首选服务端缓存的组件。而且,Redis内部是支持事务的,在使用时候能有效保证数据的一致性。
作为缓存使用时,一般有两种方式保存数据:
- 读取前,先去读Redis,如果没有数据,读取数据库,将数据拉入Redis。
- 插入数据时,同时写入Redis。
方案一:实施起来简单,但是有两个需要注意的地方:
- 避免缓存击穿。(数据库没有就需要命中的数据,导致Redis一直没有数据,而一直命中数据库。)
- 数据的实时性相对会差一点。
方案二:数据实时性强,但是开发时不便于统一处理。
当然,两种方式根据实际情况来适用。如:方案一适用于对于数据实时性要求不是特别高的场景。方案二适用于字典表、数据量不大的数据存储。
限时业务的运用
redis中可以使用expire命令设置一个键的生存时间,到时间后redis会删除它。利用这一特性可以运用在限时的优惠活动信息、手机验证码等业务场景。
计数器相关问题
redis由于incrby命令可以实现原子性的递增,所以可以运用于高并发的秒杀活动、分布式序列号的生成、具体业务还体现在比如限制一个手机号发多少条短信、一个接口一分钟限制多少请求、一个接口一天限制调用多少次等等。
分布式锁
这个主要利用redis的setnx命令进行,setnx:”set if not exists”就是如果不存在则成功设置缓存同时返回1,否则返回0 ,这个特性在很多后台中都有所运用,因为我们服务器是集群的,定时任务可能在两台机器上都会运行,所以在定时任务中首先 通过setnx设置一个lock, 如果成功设置则执行,如果没有成功设置,则表明该定时任务已执行。 当然结合具体业务,我们可以给这个lock加一个过期时间,比如说30分钟执行一次的定时任务,那么这个过期时间设置为小于30分钟的一个时间就可以,这个与定时任务的周期以及定时任务执行消耗时间相关。
在分布式锁的场景中,主要用在比如秒杀系统等。
延时操作
比如在订单生产后我们占用了库存,10分钟后去检验用户是否真正购买,如果没有购买将该单据设置无效,同时还原库存。 由于redis自2.8.0之后版本提供Keyspace Notifications功能,允许客户订阅Pub/Sub频道,以便以某种方式接收影响Redis数据集的事件。 所以我们对于上面的需求就可以用以下解决方案,我们在订单生产时,设置一个key,同时设置10分钟后过期, 我们在后台实现一个监听器,监听key的实效,监听到key失效时将后续逻辑加上。
当然我们也可以利用rabbitmq、activemq等消息中间件的延迟队列服务实现该需求。
排行榜相关问题
关系型数据库在排行榜方面查询速度普遍偏慢,所以可以借助redis的SortedSet进行热点数据的排序。
比如点赞排行榜,做一个SortedSet, 然后以用户的openid作为上面的username, 以用户的点赞数作为上面的score, 然后针对每个用户做一个hash, 通过zrangebyscore就可以按照点赞数获取排行榜,然后再根据username获取用户的hash信息,这个当时在实际运用中性能体验也蛮不错的。
点赞、好友等相互关系的存储
Redis 利用集合的一些命令,比如求交集、并集、差集等。
在微博应用中,每个用户关注的人存在一个集合中,就很容易实现求两个人的共同好友功能。
简单队列
由于Redis有list push和list pop这样的命令,所以能够很方便的执行队列操作。
Redis数据结构
首先对redis来说,所有的key(键)都是字符串。我们在谈Redis基础数据结构时,讨论的是存储值的数据类型,主要包括常见的5种数据类型,分别是:String、List、Set、Zset、Hash。
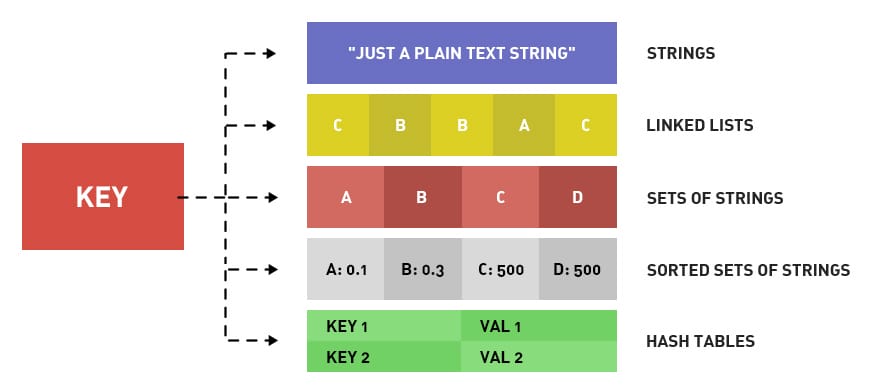
| 结构类型 | 结构存储的值 | 结构的读写能力 |
|---|---|---|
| String字符串 | 可以是字符串、整数或浮点数 | 对整个字符串或字符串的一部分进行操作;对整数或浮点数进行自增或自减操作; |
| List列表 | 一个链表,链表上的每个节点都包含一个字符串 | 对链表的两端进行push和pop操作,读取单个或多个元素;根据值查找或删除元素; |
| Set集合 | 包含字符串的无序集合 | 字符串的集合,包含基础的方法有看是否存在添加、获取、删除;还包含计算交集、并集、差集等 |
| Hash散列 | 包含键值对的无序散列表 | 包含方法有添加、获取、删除单个元素 |
| Zset有序集合 | 和散列一样,用于存储键值对 | 字符串成员与浮点数分数之间的有序映射;元素的排列顺序由分数的大小决定;包含方法有添加、获取、删除单个元素以及根据分值范围或成员来获取元素 |
String字符串
String是redis中最基本的数据类型,一个key对应一个value。
String类型是二进制安全的,意思是 redis 的 string 可以包含任何数据。如数字,字符串,JPEG 图片格式的字符串或者Json序列化的对象。
- 命令使用
| 命令 | 简述 | 使用 |
|---|---|---|
| GET | 获取存储在给定键中的值 | GET name |
| SET | 设置存储在给定键中的值 | SET name value |
| DEL | 删除存储在给定键中的值 | DEL name |
| INCR | 将键存储的值加1 | INCR key |
| DECR | 将键存储的值减1 | DECR key |
| INCRBY | 将键存储的值加上整数 | INCRBY key amount |
| DECRBY | 将键存储的值减去整数 | DECRBY key amount |
命令执行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> get hello
"world"
127.0.0.1:6379> del hello
(integer) 1
127.0.0.1:6379> get hello
(nil)
127.0.0.1:6379> set counter 2
OK
127.0.0.1:6379> get counter
"2"
127.0.0.1:6379> incr counter
(integer) 3
127.0.0.1:6379> get counter
"3"
127.0.0.1:6379> incrby counter 100
(integer) 103
127.0.0.1:6379> get counter
"103"
127.0.0.1:6379> decr counter
(integer) 102
127.0.0.1:6379> get counter
"102"
使用场景
- 缓存: 经典使用场景,把常用信息,字符串,图片或者视频等信息放到redis中,作为缓存层,数据库做持久化,降低数据库的读写压力。
- 计数器:redis是单线程模型,一个命令执行完才会执行下一个,同时数据可以一步落地到其他的数据源。可以用来记录网站访问量,某个文件的下载量,签到人数,视频访问量等等。
- 时间内限制请求次数:比如已登录用户请求短信验证码,验证码在5分钟内有效的场景。当用户首次请求了短信接口,将用户id存储到redis 已经发送短信的字符串中,并且设置过期时间为5分钟。当该用户再次请求短信接口,发现已经存在该用户发送短信记录,则不再发送短信。
- session:常见方案spring session + redis实现session共享。当用nginx做负载均衡的时候,如果我们每个从服务器上都各自存储自己的session,那么当切换了服务器后,session信息会由于不共享而会丢失,不得不考虑第三应用来存储session。
List列表
Redis中的List其实就是链表(Redis用双端链表实现List)。
使用List结构,可以轻松地实现最新消息排队功能(比如新浪微博的TimeLine)。List的另一个应用就是消息队列,可以利用List的 PUSH 操作,将任务存放在List中,然后工作线程再用 POP 操作将任务取出进行执行。
- 命令使用
| 命令 | 简述 | 使用 |
|---|---|---|
| RPUSH | 将给定值推入到列表右端 | RPUSH key value |
| LPUSH | 将给定值推入到列表左端 | LPUSH key value |
| RPOP | 从列表的右端弹出一个值,并返回被弹出的值 | RPOP key |
| LPOP | 从列表的左端弹出一个值,并返回被弹出的值 | LPOP key |
| LRANGE | 获取列表在给定范围上的所有值 | LRANGE key 0 -1 |
| LINDEX | 通过索引获取列表中的元素。你也可以使用负数下标,以 -1 表示列表的最后一个元素, -2 表示列表的倒数第二个元素,以此类推。 | LINDEX key index |
使用列表的技巧
- lpush+lpop=Stack(栈)
- lpush+rpop=Queue(队列)
- lpush+ltrim=Capped Collection(有限集合)
- lpush+brpop=Message Queue(消息队列)
命令执行
1 | 127.0.0.1:6379> lpush mylist 1 2 ll ls mem |
- 使用场景
- 微博TimeLine: 有人发布微博,用lpush加入时间轴,展示新的列表信息。朋友圈的点赞列表、评论列表、排行榜。
- 消息队列 :lpush+rpop,但是这样用redis作为消息队列是不安全的,它
不能重复消费,一旦消费就会被删除,同时做消费者确认ACK也麻烦所以一般在实际开发中一般很少用redis中消息队列,因为现在已经有Kafka、NSQ、RabbitMQ等成熟的消息队列了,它们的功能更加完善。
Set集合
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。内部实现相当于一个特殊的字典,字典中所有的value都是一个值 NULL。当集合中最后一个元素被移除之后,数据结构被自动删除,内存被回收。
Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
- 命令使用
| 命令 | 简述 | 使用 |
|---|---|---|
| SADD | 向集合添加一个或多个成员,若key不存在,创建该key | SADD key value1 value2 |
| SCARD | 获取集合的成员数 | SCARD key |
| SMEMBERS | 返回集合中的所有成员 | SMEMBERS key [count] |
| SISMEMBER | 判断 member 元素是否是集合 key 的成员 | SISMEMBER key [count] |
| SPOP | 移除并返回集合中的一个或多个随机元素 | SPOP key [count] |
| SREM | 移除集合中一个或多个成员 | SREM key value1 value2 |
| SRANDMEMBER | 返回集合中一个或多个随机数 | SRANDMEMBER key [count] |
| SMOVE | 将 member 元素从 source 集合移动到 destination 集合 | SMOVE source destination member |
其它一些集合操作,请参考这里https://www.runoob.com/redis/redis-sets.html
- 命令执行
1 | 127.0.0.1:6379> sadd myset hao hao1 xiaohao hao |
- 使用场景
- 标签(tag),给用户添加标签,或者用户给消息添加标签,这样有同一标签或者类似标签的可以给推荐关注的事或者关注的人。
- 点赞,或点踩,收藏等,可以放到set中实现。保证一个用户只能点一个赞。key 可以是某某文章、微信朋友圈的文章id
- 抽奖活动:存储某活动中中奖的用户ID ,因为有去重功能,可以保证同一个用户不会中奖两次。
Hash散列
Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。
- 命令使用
| 命令 | 简述 | 使用 |
|---|---|---|
| HSET | 添加键值对 | HSET hash-key sub-key1 value1 |
| HGET | 获取指定散列键的值 | HGET hash-key key1 |
| HGETALL | 获取散列中包含的所有键值对 | HGETALL hash-key |
| HDEL | 如果给定键存在于散列中,那么就移除这个键 | HDEL hash-key sub-key1 |
- 命令执行
1 | 127.0.0.1:6379> hset user name1 hao |
使用场景
缓存: 能直观,更节省空间(相比string)的维护缓存信息,如用户信息,视频信息等。
存储对象: 哈希对象常常用来缓存一些对象信息,如用户信息、商品信息、配置信息等。
我们以用户信息为例,它在关系型数据库中的结构是这样的:
id name age 1 Tom 15 2 Jerry 13 使用Redis Hash存储其结构如下图:
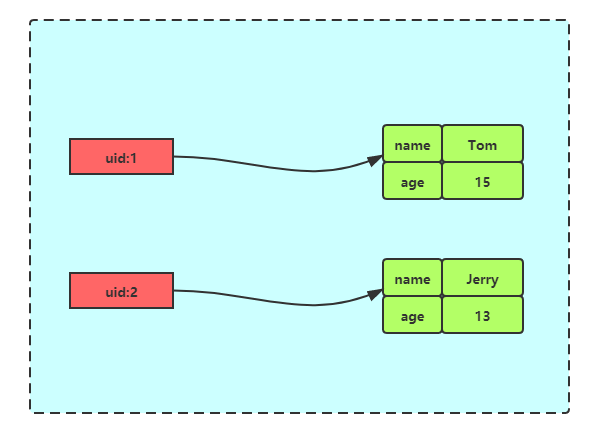
1
2hmset user:1 name Tom age 15
hmset user:2 name Jerry age 13相比较于使用Redis字符串存储,其有以下几个优缺点:
- 原生字符串每个属性一个键。占用过多的键,内存占用量较大,同时用户信息内聚性比较差。
- 序列化字符串后,将用户信息序列化后用一个键保存,简化编程,序列化和反序列化有一定的开销,同时每次更新属性都需要把全部数据取出进行反序列化,更新后再序列化到Redis中。
Redisson分布式锁: Redisson在实现分布式锁的时候,内部的用的数据就是hash而不是String。因为Redisson为了实现可重入加锁机制。所以在hash中存入了当前线程ID。
购物车列表:以用户id为key,商品id为field,商品数量为value,恰好构成了购物车的3个要素。优点:无须对数据库进行写入就可以实现购物车功能,这种方式大大提高了购物车的性能。缺点:程序需要重新解析和验证( validate) cookie,确保 cookie 的格式正确,并且包含的商品都是真正可购买的商品。另外,因为浏览器每次发送请求都会连 cookie 一起发送,所以如果购物车 cookie 的体积比较大,那么请求发送和处理的速度可能会有所降低。
底层实现
底层存储结构有两种实现方式:
- ziplist
- 哈希表
第一种,当存储的数据量较少的时,hash 采用 ziplist 作为底层存储结构,此时要求符合以下两个条件:
- 哈希对象保存的所有键值对(键和值)的字符串长度总和小于 64 个字节。
- 哈希对象保存的键值对数量要小于 512 个。
当无法满足上述条件时,hash 就会采用第二种方式来存储数据,也就是哈希表。因此其查找性能非常高效,其时间复杂度为 O(1)。
哈希表又称散列表,其初衷是将数据映射到数组中的某个位置上,这样就能够通过数组下标来访问该数据,从而提高数据的查找效率。
ziplist压缩列表
官方文档中关于 ziplist 的介绍如下:
1 | /* The ziplist is a specially encoded dually linked list that is designed |
ziplist 是一个经过特殊编码的双向链表,它的设计目标是节约内存。它可以存储字符串或者整数。其中整数是按二进制进行编码的,而不是字符串序列。它能以 O(1) 的时间复杂度在列表的两端进行 push 和 pop 操作。但是由于每个操作都需要对 ziplist 所使用的内存进行重新分配,所以实际操作的复杂度与 ziplist 占用内存大小有关。
ziplist 的设计目标是为了 节约内存,而链表的各项之间需要使用指针连接起来,这种方式会带来大量的内存碎片,而且地址指针也会占用额外的内存,这与 ziplist 的设计初衷不符。而且看了 ziplist 的数据结构就会发现,ziplist 实际上是一块连续的内存。
因此可以这么理解:ziplist 是一个特殊的双向链表,特殊之处在于:没有维护双向指针,prev、next,而是存储了上一个 entry 的长度和当前 entry 的长度,通过长度推算下一个元素。
总结
- 压缩列表本质上就是一个字节数组
- 是 Redis 为了节约内存而设计的一种线性结构
- 可以包含多个元素,每个元素可以是一个字节数组或一个整数
压缩列表的各个组成部分:

图中各字段含义如下:
| 属性 | 类型 | 长度 | 用途 |
|---|---|---|---|
| zlbytes | uint32_t | 4 字节 | 记录整个压缩列表占用的内存字节数:在对压缩列表进行内存重分配,或者计算 zlend 的位置时使用。 |
| zltail | uint32_t | 4 字节 | 记录压缩列表表尾节点距离压缩列表的起始地址有多少字节:通过这个偏移量,程序无需遍历整个压缩列表就可以确定表尾节点的地址。 |
| zllen | uint16_t | 2 字节 | 记录了压缩列表包含的节点数量,当这个属性的值小于 UINT16_MAX(65535)时,这个属性的值就是压缩列表包含节点的数量;当这个值等于 UINT16_MAX 时,节点的真实数量需要遍历整个压缩列表才能计算得出。 |
| entry | 列表节点 | 不定 | 压缩列表包含的各个节点,节点的长度由节点保存的内容决定。 |
| zlend | uint8_t | 1 字节 | 特殊值 0xFF(十进制 255),用于标记压缩列表的末端。 |
来看一个包含三个节点的压缩列表示例:
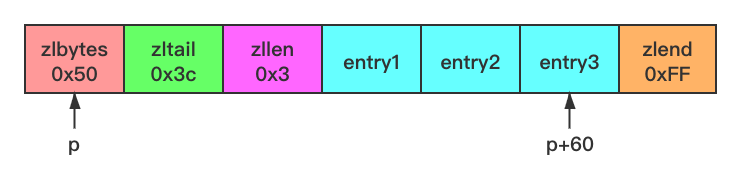
- 列表 zlbytes 属性的值为 0x50(十进制 80),表示压缩列表的总长为 80 字节。
- 列表 zltail 属性的值为 0x3c(十进制 60),这表示如果我们有一个指向压缩列表起始地址的指针 p,那么只要用指针 p 加上偏移量 60,就可以计算出表尾节点 entry3 的地址。
- 列表 zllen 属性的值为 0x3(十进制 3),表示压缩列表包含三个节点。
假如 char * zl 指向压缩列表的首地址,Redis 可通过以下宏定义实现压缩列表的各个字段的存取操作。
1 |
|
了解了压缩列表的数据结构,可以很容易的获得压缩列表的字节长度、元素个数等,那么如何遍历压缩列表呢?对于任意一个元素,如何判断其存储的是什么类型呢?如何获取字节数组的长度呢?
回答这些问题之前,需要了解压缩列表元素的数据结构:
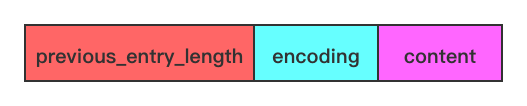
previous_entry_length字段表示前一个元素的字节长度,占 1 个或者 5 个字节:- 当前一个元素的长度小于 254 字节时,用 1 个字节表示;
- 当前一个元素的长度大于或等于 254 字节时,用 5 个字节来表示。而此时
previous_entry_length字段的第一个字节是固定的 0xFE(十进制为 254),后面 4 个字节才真正表示前一个元素的长度。 - 假设已知当前元素的首地址为 p,那么
p-previous_entry_length就是前一个元素的首地址,从而实现压缩列表从尾到头的遍历。
encoding字段表示当前元素的编码,记录了节点的 content 字段所保存数据的类型以及长度:- 1 字节、2 字节或者 5 字节长,值的最高位为 00、01 或者 10 的是字节数组编码:这种编码表示节点的 content 属性保存着字节数组,数组的长度由编码除去最高两位之后的其他位记录;
- 1 字节长,值的最高位以 11 开头的是整数编码:这种编码表示节点的 content 字段保存着整数值,整数值的类型和长度由编码除去最高两位之后的其他位记录;
content字段存储节点的值,节点值可以是一个字节数组或者整数,值的类型和长度由节点的 encoding 属性决定。
下表记录了压缩列表的元素编码,表格中的下划线“_”表示留空,而 b、x 等变量则代表实际的二进制数据,为了方便阅读,多个字节之间用空格隔开。
Zset有序集合
Redis 有序集合和集合一样也是 string 类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。
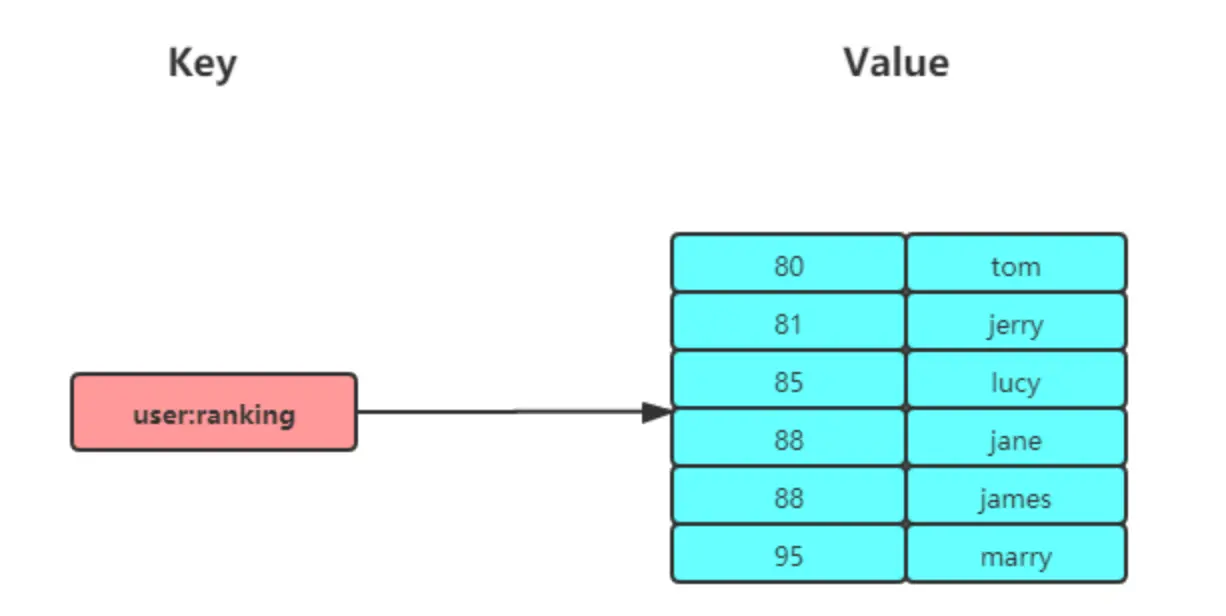
有序集合的成员是唯一的, 但分数(score)却可以重复。有序集合是通过两种数据结构实现:
- 如果有序集合的元素个数小于
128个,并且每个元素的值小于64字节时,Redis 会使用压缩列表作为 Zset 类型的底层数据结构; - 如果有序集合的元素不满足上面的条件,Redis 会使用跳表作为 Zset 类型的底层数据结构;
- 在 Redis 7.0 中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现了
压缩列表(ziplist): ziplist是为了提高存储效率而设计的一种特殊编码的双向链表。它可以存储字符串或者整数,存储整数时是采用整数的二进制而不是字符串形式存储。它能在O(1)的时间复杂度下完成list两端的push和pop操作。但是因为每次操作都需要重新分配ziplist的内存,所以实际复杂度和ziplist的内存使用量相关
跳跃表(zSkiplist): 跳跃表的性能可以保证在查找,删除,添加等操作的时候在对数期望时间内完成,这个性能是可以和平衡树来相比较的,而且在实现方面比平衡树要优雅,这是采用跳跃表的主要原因。跳跃表的复杂度是O(log(n))。
- 命令使用
| 命令 | 简述 | 使用 |
|---|---|---|
| ZADD | 将一个带有给定分值的成员添加到有序集合里面 | ZADD zset-key 178 member1 |
| ZRANGE | 根据元素在有序集合中所处的位置,从有序集合中获取多个元素 | ZRANGE zset-key 0-1 withccores |
| ZREM | 如果给定元素成员存在于有序集合中,那么就移除这个元素 | ZREM zset-key member1 |
1 | 往有序集合key中加入带分值元素 |
更多命令请参考这里 https://www.runoob.com/redis/redis-sorted-sets.html
- 命令执行
1 | 127.0.0.1:6379> zadd myscoreset 100 hao 90 xiaohao |
- 使用场景
- 排行榜:有序集合经典使用场景。例如小说视频等网站需要对用户上传的小说视频做排行榜,榜单可以按照用户关注数,更新时间,字数等打分,做排行。
- 电话、姓名排序: 使用有序集合的
ZRANGEBYLEX或ZREVRANGEBYLEX可以帮助我们实现电话号码或姓名的排序,我们以ZRANGEBYLEX(返回指定成员区间内的成员,按 key 正序排列,分数必须相同)为例。
特殊数据类型详解
HyperLogLogs(基数统计)
Redis 2.8.9 版本更新了 Hyperloglog 数据结构!是一种用于「统计基数」的数据集合类型,基数统计就是指统计一个集合中不重复的元素个数。但要注意,HyperLogLog 是统计规则是基于概率完成的,不是非常准确,标准误算率是 0.81%。
所以,简单来说 HyperLogLog 提供不精确的去重计数。
HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的内存空间总是固定的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数,和元素越多就越耗费内存的 Set 和 Hash 类型相比,HyperLogLog 就非常节省空间。
- 什么是基数?
举个例子,A = {1, 2, 3, 4, 5}, B = {3, 5, 6, 7, 9};那么基数(不重复的元素)= 1, 2, 4, 6, 7, 9; (允许容错,即可以接受一定误差)
- HyperLogLogs 基数统计用来解决什么问题?
这个结构可以非常省内存的去统计各种计数,比如注册 IP 数、每日访问 IP 数、页面实时UV、在线用户数,共同好友数等。
- 它的优势体现在哪?
一个大型的网站,每天 IP 比如有 100 万,粗算一个 IP 消耗 15 字节,那么 100 万个 IP 就是 15M。而 HyperLogLog 在 Redis 中每个键占用的内容都是 12K,理论存储近似接近 2^64 个值,不管存储的内容是什么,它一个基于基数估算的算法,只能比较准确的估算出基数,可以使用少量固定的内存去存储并识别集合中的唯一元素。而且这个估算的基数并不一定准确,是一个带有 0.81% 标准错误的近似值(对于可以接受一定容错的业务场景,比如IP数统计,UV等,是可以忽略不计的)。
- 相关命令使用
1 | 127.0.0.1:6379> pfadd key1 a b c d e f g h i # 创建第一组元素 |
应用场景
百万级网页 UV 计数
Redis HyperLogLog 优势在于只需要花费 12 KB 内存,就可以计算接近 2^64 个元素的基数,和元素越多就越耗费内存的 Set 和 Hash 类型相比,HyperLogLog 就非常节省空间。
所以,非常适合统计百万级以上的网页 UV 的场景。
在统计 UV 时,你可以用 PFADD 命令(用于向 HyperLogLog 中添加新元素)把访问页面的每个用户都添加到 HyperLogLog 中。
1 | PFADD page1:uv user1 user2 user3 user4 user5 |
接下来,就可以用 PFCOUNT 命令直接获得 page1 的 UV 值了,这个命令的作用就是返回 HyperLogLog 的统计结果。
1 | PFCOUNT page1:uv |
不过,有一点需要注意,HyperLogLog 的统计规则是基于概率完成的,所以它给出的统计结果是有一定误差的,标准误算率是 0.81%。
这也就意味着,你使用 HyperLogLog 统计的 UV 是 100 万,但实际的 UV 可能是 101 万。虽然误差率不算大,但是,如果你需要精确统计结果的话,最好还是继续用 Set 或 Hash 类型。
Bitmap (位存储)
Bitmap,即位图,是一串连续的二进制数组(0和1),可以通过偏移量(offset)定位元素。BitMap通过最小的单位bit来进行0|1的设置,表示某个元素的值或者状态,时间复杂度为O(1)。
由于 bit 是计算机中最小的单位,使用它进行储存将非常节省空间,特别适合一些数据量大且使用二值统计的场景。

内部实现
Bitmap 本身是用 String 类型作为底层数据结构实现的一种统计二值状态的数据类型。
String 类型是会保存为二进制的字节数组,所以,Redis 就把字节数组的每个 bit 位利用起来,用来表示一个元素的二值状态,你可以把 Bitmap 看作是一个 bit 数组。
- 用来解决什么问题?
比如:统计用户信息,活跃,不活跃! 登录,未登录! 打卡,不打卡! 两个状态的,都可以使用 Bitmaps!
如果存储一年的打卡状态需要多少内存呢? 365 天 = 365 bit 1字节 = 8bit 46 个字节左右!
- 相关命令使用
bitmap 基本操作:
1 | 设置值,其中value只能是 0 和 1 |
bitmap 运算操作:
1 | BitMap间的运算 |
使用bitmap 来记录 周一到周日的打卡! 周一:1 周二:0 周三:0 周四:1 ……
1 | 127.0.0.1:6379> setbit sign 0 1 |
查看某一天是否有打卡!
1 | 127.0.0.1:6379> getbit sign 3 |
统计操作,统计 打卡的天数!
1 | 127.0.0.1:6379> bitcount sign # 统计这周的打卡记录,就可以看到是否有全勤! |
应用场景
Bitmap 类型非常适合二值状态统计的场景,这里的二值状态就是指集合元素的取值就只有 0 和 1 两种,在记录海量数据时,Bitmap 能够有效地节省内存空间。
签到统计
在签到打卡的场景中,我们只用记录签到(1)或未签到(0),所以它就是非常典型的二值状态。
签到统计时,每个用户一天的签到用 1 个 bit 位就能表示,一个月(假设是 31 天)的签到情况用 31 个 bit 位就可以,而一年的签到也只需要用 365 个 bit 位,根本不用太复杂的集合类型。
假设我们要统计 ID 100 的用户在 2022 年 6 月份的签到情况,就可以按照下面的步骤进行操作。
第一步,执行下面的命令,记录该用户 6 月 3 号已签到。
判断用户登陆态
Bitmap 提供了 GETBIT、SETBIT 操作,通过一个偏移值 offset 对 bit 数组的 offset 位置的 bit 位进行读写操作,需要注意的是 offset 从 0 开始。
只需要一个 key = login_status 表示存储用户登陆状态集合数据, 将用户 ID 作为 offset,在线就设置为 1,下线设置 0。通过 GETBIT判断对应的用户是否在线。 5000 万用户只需要 6 MB 的空间。
假如我们要判断 ID = 10086 的用户的登陆情况:
第一步,执行以下指令,表示用户已登录。
1 | SETBIT login_status 10086 1 |
第二步,检查该用户是否登陆,返回值 1 表示已登录。
1 | GETBIT login_status 10086 |
第三步,登出,将 offset 对应的 value 设置成 0。
1 | SETBIT login_status 10086 0 |
连续签到用户数
如何统计出这连续 7 天连续打卡用户总数呢?
我们把每天的日期作为 Bitmap 的 key,userId 作为 offset,若是打卡则将 offset 位置的 bit 设置成 1。
key 对应的集合的每个 bit 位的数据则是一个用户在该日期的打卡记录。
一共有 7 个这样的 Bitmap,如果我们能对这 7 个 Bitmap 的对应的 bit 位做 『与』运算。同样的 UserID offset 都是一样的,当一个 userID 在 7 个 Bitmap 对应对应的 offset 位置的 bit = 1 就说明该用户 7 天连续打卡。
结果保存到一个新 Bitmap 中,我们再通过 BITCOUNT 统计 bit = 1 的个数便得到了连续打卡 7 天的用户总数了。
Redis 提供了 BITOP operation destkey key [key ...]这个指令用于对一个或者多个 key 的 Bitmap 进行位元操作。
operation可以是and、OR、NOT、XOR。当 BITOP 处理不同长度的字符串时,较短的那个字符串所缺少的部分会被看作0。空的key也被看作是包含0的字符串序列。
假设要统计 3 天连续打卡的用户数,则是将三个 bitmap 进行 AND 操作,并将结果保存到 destmap 中,接着对 destmap 执行 BITCOUNT 统计,如下命令:
1 | # 与操作 |
即使一天产生一个亿的数据,Bitmap 占用的内存也不大,大约占 12 MB 的内存(10^8/8/1024/1024),7 天的 Bitmap 的内存开销约为 84 MB。同时我们最好给 Bitmap 设置过期时间,让 Redis 删除过期的打卡数据,节省内存。
geospatial (地理位置)
Redis 的 Geo 在 Redis 3.2 版本就推出了! 这个功能可以推算地理位置的信息: 两地之间的距离, 方圆几里的人
geoadd
添加地理位置
1 | 127.0.0.1:6379> geoadd china:city 118.76 32.04 manjing 112.55 37.86 taiyuan 123.43 41.80 shenyang |
规则
两级无法直接添加,一般会下载城市数据
- 有效的经度从-180度到180度。
- 有效的纬度从-85.05112878度到85.05112878度。
1 | # 当坐标位置超出上述指定范围时,该命令将会返回一个错误。 |
geopos
获取指定的成员的经度和纬度
1 | 127.0.0.1:6379> geopos china:city taiyuan manjing |
获得当前定位, 一定是一个坐标值!
geodist
如果不存在, 返回空
单位如下
- m
- km
- mi 英里
- ft 英尺
1 | 127.0.0.1:6379> geodist china:city taiyuan shenyang m |
georadius
附近的人 ==> 获得所有附近的人的地址, 定位, 通过半径来查询
获得指定数量的人
1 | 127.0.0.1:6379> georadius china:city 110 30 1000 km 以 100,30 这个坐标为中心, 寻找半径为1000km的城市 |
参数 key 经度 纬度 半径 单位 [显示结果的经度和纬度] [显示结果的距离] [显示的结果的数量]
georadiusbymember
显示与指定成员一定半径范围内的其他成员
1 | 127.0.0.1:6379> georadiusbymember china:city taiyuan 1000 km |
参数与 georadius 一样
geohash
该命令返回11个字符的hash字符串
1 | 127.0.0.1:6379> geohash china:city taiyuan shenyang |
将二维的经纬度转换为一维的字符串, 如果两个字符串越接近, 则距离越近
底层
geo底层的实现原理实际上就是Zset, 我们可以通过Zset命令来操作geo
1 | 127.0.0.1:6379> type china:city |
查看全部元素 删除指定的元素
1 | 127.0.0.1:6379> zrange china:city 0 -1 withscores |
Stream
Redis5.0 中还增加了一个数据类型Stream,它借鉴了Kafka的设计,是一个新的强大的支持多播的可持久化的消息队列。
为什么会设计Stream
在 Redis 5.0 Stream 没出来之前,消息队列的实现方式都有着各自的缺陷,例如:
- 发布订阅模式,不能持久化也就无法可靠的保存消息,并且对于离线重连的客户端不能读取历史消息的缺陷;
- List 实现消息队列的方式不能重复消费,一个消息消费完就会被删除,而且生产者需要自行实现全局唯一 ID。不支持多播,分组消费等
这就是stream设计的原因,完美地实现消息队列,它支持消息的持久化、支持自动生成全局唯一 ID、支持 ack 确认消息的模式、支持消费组模式等,让消息队列更加的稳定和可靠。
如果期望设计一种数据结构来实现消息队列,最重要的就是要理解设计一个消息队列需要考虑什么?初步的我们很容易想到
- 消息的生产
- 消息的消费
- 单播和多播(多对多)
- 阻塞和非阻塞读取
- 消息有序性
- 消息的持久化
Redis考虑了哪些设计?
- 消息ID的序列化生成
- 消息遍历
- 消息的阻塞和非阻塞读取
- 消息的分组消费
- 未完成消息的处理
- 消息队列监控
这也是我们需要理解Stream的点,但是结合上面的图,我们也应该理解Redis Stream也是一种超轻量MQ并没有完全实现消息队列所有设计要点,这决定着它适用的场景。
Stream详解
经过梳理总结,我认为从以下几个大的方面去理解Stream是比较合适的,总结如下:
- Stream的结构设计
- 生产和消费
- 基本的增删查改
- 单一消费者的消费
- 消费组的消费
- 监控状态
Stream的结构
每个 Stream 都有唯一的名称,它就是 Redis 的 key,在我们首次使用 xadd 指令追加消息时自动创建。
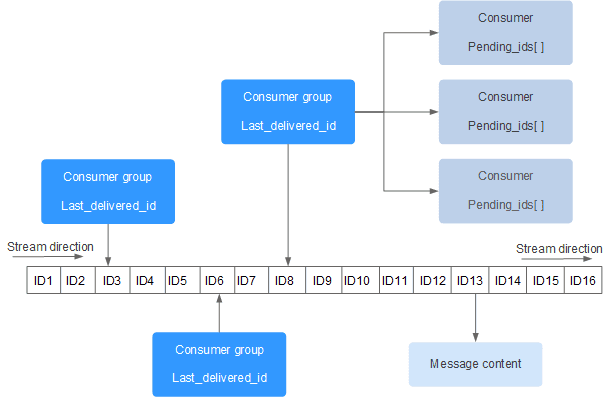
上图解析:
Consumer Group:消费组,使用 XGROUP CREATE 命令创建,一个消费组有多个消费者(Consumer), 这些消费者之间是竞争关系。last_delivered_id:游标,每个消费组会有个游标 last_delivered_id,任意一个消费者读取了消息都会使游标 last_delivered_id 往前移动。pending_ids:消费者(Consumer)的状态变量,作用是维护消费者的未确认的 id。 pending_ids 记录了当前已经被客户端读取的消息,但是还没有ack(Acknowledge character:确认字符)。如果客户端没有ack,这个变量里面的消息ID会越来越多,一旦某个消息被ack,它就开始减少。这个pending_ids变量在Redis官方被称之为PEL,也就是Pending Entries List,这是一个很核心的数据结构,它用来确保客户端至少消费了消息一次,而不会在网络传输的中途丢失了没处理。
此外我们还需要理解两点:
消息ID: 消息ID的形式是timestampInMillis-sequence,例如1527846880572-5,它表示当前的消息在毫米时间戳1527846880572时产生,并且是该毫秒内产生的第5条消息。消息ID可以由服务器自动生成,也可以由客户端自己指定,但是形式必须是整数-整数,而且必须是后面加入的消息的ID要大于前面的消息ID。消息内容: 消息内容就是键值对,形如hash结构的键值对,这没什么特别之处。
增删改查
消息队列相关命令:
- XADD - 添加消息到末尾
- XTRIM - 对流进行修剪,限制长度
- XDEL - 删除消息
- XLEN - 获取流包含的元素数量,即消息长度
- XRANGE - 获取消息列表,会自动过滤已经删除的消息
- XREVRANGE - 反向获取消息列表,ID 从大到小
- XREAD - 以阻塞或非阻塞方式获取消息列表
1 | *号表示服务器自动生成ID,后面顺序跟着一堆key/value |
独立消费
我们可以在不定义消费组的情况下进行Stream消息的独立消费,当Stream没有新消息时,甚至可以阻塞等待。Redis设计了一个单独的消费指令xread,可以将Stream当成普通的消息队列(list)来使用。使用xread时,我们可以完全忽略消费组(Consumer Group)的存在,就好比Stream就是一个普通的列表(list)。
1 | # 从Stream头部读取两条消息 |
客户端如果想要使用xread进行顺序消费,一定要记住当前消费到哪里了,也就是返回的消息ID。下次继续调用xread时,将上次返回的最后一个消息ID作为参数传递进去,就可以继续消费后续的消息。
block 0表示永远阻塞,直到消息到来,block 1000表示阻塞1s,如果1s内没有任何消息到来,就返回nil
1 | 127.0.0.1:6379> xread block 1000 count 1 streams codehole $ |
消费组消费
- 消费组消费图
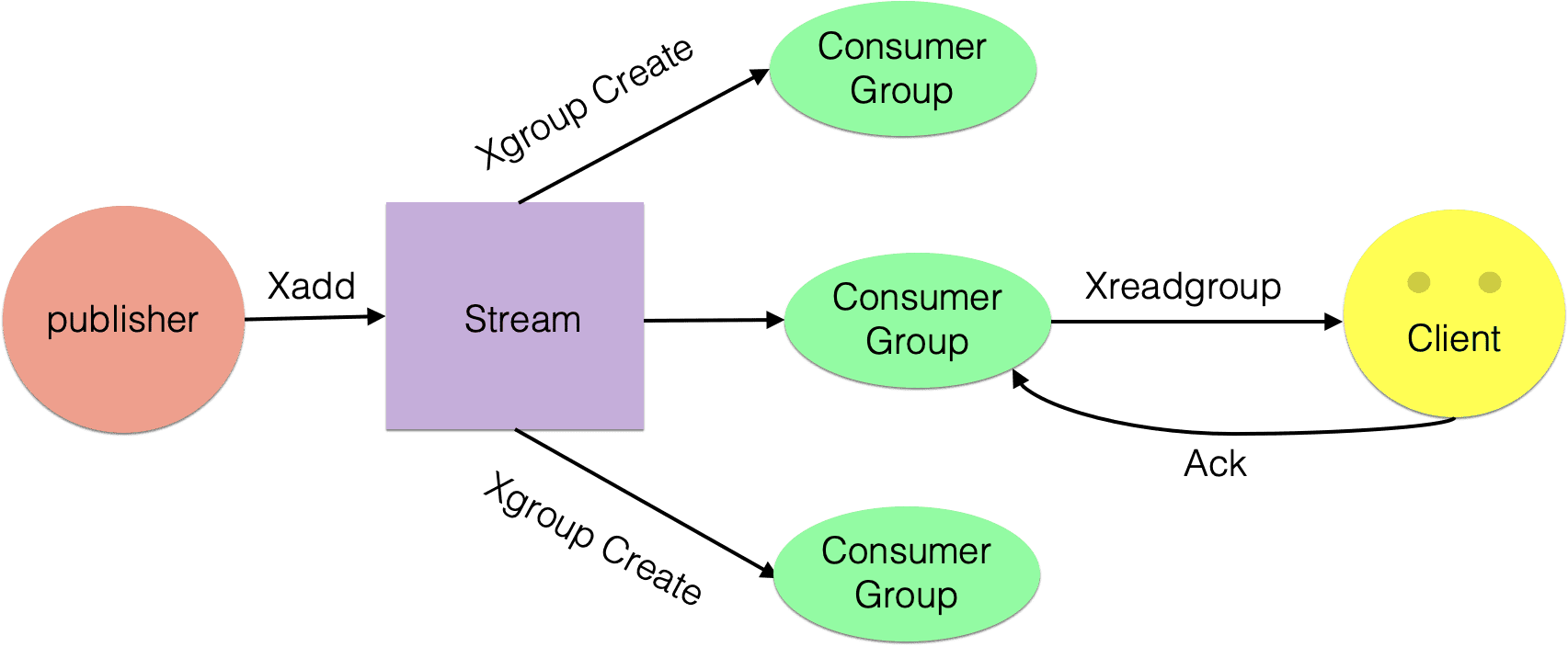
相关命令:
- XGROUP CREATE - 创建消费者组
- XREADGROUP GROUP - 读取消费者组中的消息
- XACK - 将消息标记为”已处理”
- XGROUP SETID - 为消费者组设置新的最后递送消息ID
- XGROUP DELCONSUMER - 删除消费者
- XGROUP DESTROY - 删除消费者组
- XPENDING - 显示待处理消息的相关信息
- XCLAIM - 转移消息的归属权
- XINFO - 查看流和消费者组的相关信息;
- XINFO GROUPS - 打印消费者组的信息;
- XINFO STREAM - 打印流信息
创建消费组
Stream通过xgroup create指令创建消费组(Consumer Group),需要传递起始消息ID参数用来初始化last_delivered_id变量。
1 | 127.0.0.1:6379> xgroup create codehole cg1 0-0 # 表示从头开始消费 |
- 消费组消费
Stream提供了xreadgroup指令可以进行消费组的组内消费,需要提供消费组名称、消费者名称和起始消息ID。它同xread一样,也可以阻塞等待新消息。读到新消息后,对应的消息ID就会进入消费者的PEL(正在处理的消息)结构里,客户端处理完毕后使用xack指令通知服务器,本条消息已经处理完毕,该消息ID就会从PEL中移除。
1 | # >号表示从当前消费组的last_delivered_id后面开始读 |
信息监控
Stream提供了XINFO来实现对服务器信息的监控,可以查询:
- 查看队列信息
1 | 127.0.0.1:6379> Xinfo stream mq |
- 消费组信息
1 | 127.0.0.1:6379> Xinfo groups mq |
- 消费者组成员信息
1 | 127.0.0.1:6379> XINFO CONSUMERS mq mqGroup |
至此,消息队列的操作说明大体结束!
更深入理解
我们结合MQ中常见问题,看Redis是如何解决的,来进一步理解Redis。
Stream用在什么样场景
可用作时通信等,大数据分析,异地数据备份等
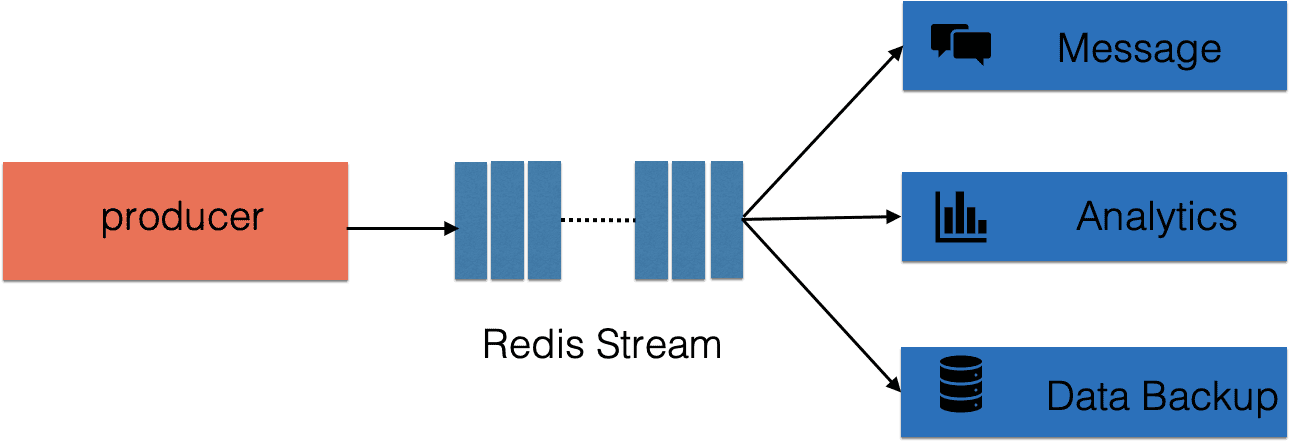
客户端可以平滑扩展,提高处理能力
消息ID的设计是否考虑了时间回拨的问题?
在 分布式算法 - ID算法设计中, 一个常见的问题就是时间回拨问题,那么Redis的消息ID设计中是否考虑到这个问题呢?
XADD生成的1553439850328-0,就是Redis生成的消息ID,由两部分组成:时间戳-序号。时间戳是毫秒级单位,是生成消息的Redis服务器时间,它是个64位整型(int64)。序号是在这个毫秒时间点内的消息序号,它也是个64位整型。
可以通过multi批处理,来验证序号的递增:
1 | 127.0.0.1:6379> MULTI |
由于一个redis命令的执行很快,所以可以看到在同一时间戳内,是通过序号递增来表示消息的。
为了保证消息是有序的,因此Redis生成的ID是单调递增有序的。由于ID中包含时间戳部分,为了避免服务器时间错误而带来的问题(例如服务器时间延后了),Redis的每个Stream类型数据都维护一个latest_generated_id属性,用于记录最后一个消息的ID。若发现当前时间戳退后(小于latest_generated_id所记录的),则采用时间戳不变而序号递增的方案来作为新消息ID(这也是序号为什么使用int64的原因,保证有足够多的的序号),从而保证ID的单调递增性质。
强烈建议使用Redis的方案生成消息ID,因为这种时间戳+序号的单调递增的ID方案,几乎可以满足你全部的需求。但同时,记住ID是支持自定义的,别忘了!
消费者崩溃带来的会不会消息丢失问题?
为了解决组内消息读取但处理期间消费者崩溃带来的消息丢失问题,STREAM 设计了 Pending 列表,用于记录读取但并未处理完毕的消息。命令XPENDIING 用来获消费组或消费内消费者的未处理完毕的消息。演示如下:
1 | 127.0.0.1:6379> XPENDING mq mqGroup # mpGroup的Pending情况 |
每个Pending的消息有4个属性:
- 消息ID
- 所属消费者
- IDLE,已读取时长
- delivery counter,消息被读取次数
上面的结果我们可以看到,我们之前读取的消息,都被记录在Pending列表中,说明全部读到的消息都没有处理,仅仅是读取了。那如何表示消费者处理完毕了消息呢?使用命令 XACK 完成告知消息处理完成,演示如下:
1 | 127.0.0.1:6379> XACK mq mqGroup 1553585533795-0 # 通知消息处理结束,用消息ID标识 |
有了这样一个Pending机制,就意味着在某个消费者读取消息但未处理后,消息是不会丢失的。等待消费者再次上线后,可以读取该Pending列表,就可以继续处理该消息了,保证消息的有序和不丢失。
消费者彻底宕机后如何转移给其它消费者处理?
还有一个问题,就是若某个消费者宕机之后,没有办法再上线了,那么就需要将该消费者Pending的消息,转义给其他的消费者处理,就是消息转移。
消息转移的操作时将某个消息转移到自己的Pending列表中。使用语法XCLAIM来实现,需要设置组、转移的目标消费者和消息ID,同时需要提供IDLE(已被读取时长),只有超过这个时长,才能被转移。演示如下:
1 | # 当前属于消费者A的消息1553585533795-1,已经15907,787ms未处理了 |
以上代码,完成了一次消息转移。转移除了要指定ID外,还需要指定IDLE,保证是长时间未处理的才被转移。被转移的消息的IDLE会被重置,用以保证不会被重复转移,以为可能会出现将过期的消息同时转移给多个消费者的并发操作,设置了IDLE,则可以避免后面的转移不会成功,因为IDLE不满足条件。例如下面的连续两条转移,第二条不会成功。
1 | 127.0.0.1:6379> XCLAIM mq mqGroup consumerB 3600000 1553585533795-1 |
这就是消息转移。至此我们使用了一个Pending消息的ID,所属消费者和IDLE的属性,还有一个属性就是消息被读取次数,delivery counter,该属性的作用由于统计消息被读取的次数,包括被转移也算。这个属性主要用在判定是否为错误数据上。
坏消息问题,Dead Letter,死信问题
正如上面所说,如果某个消息,不能被消费者处理,也就是不能被XACK,这是要长时间处于Pending列表中,即使被反复的转移给各个消费者也是如此。此时该消息的delivery counter就会累加(上一节的例子可以看到),当累加到某个我们预设的临界值时,我们就认为是坏消息(也叫死信,DeadLetter,无法投递的消息),由于有了判定条件,我们将坏消息处理掉即可,删除即可。删除一个消息,使用XDEL语法,演示如下:
1 | # 删除队列中的消息 |
注意本例中,并没有删除Pending中的消息因此你查看Pending,消息还会在。可以执行XACK标识其处理完毕!
持久化
Redis是一个内存数据库,所有的数据将保存在内存中,这与传统的MySQL、Oracle、SqlServer等关系型数据库直接把数据保存到硬盘相比,Redis的读写效率非常高。但是保存在内存中也有一个很大的缺陷,一旦断电或者宕机,内存数据库中的内容将会全部丢失。
通常的解决方案是从后端数据库恢复这些数据,但后端数据库有性能瓶颈,如果是大数据量的恢复,1、会对数据库带来巨大的压力,2、数据库的性能不如Redis。
为了弥补这一缺陷,Redis提供了把内存数据持久化到硬盘文件,以及通过备份文件来恢复数据的功能,即Redis持久化机制。避免从后端数据库中恢复数据。
从严格意义上说,Redis服务提供四种持久化存储方案:RDB、AOF、虚拟内存(VM)和 DISKSTORE。虚拟内存(VM)方式,从Redis Version 2.4开始就被官方明确表示不再建议使用,Version 3.2版本中更找不到关于虚拟内存(VM)的任何配置范例,Redis的主要作者Salvatore Sanfilippo还专门写了一篇论文,来反思Redis对虚拟内存(VM)存储技术的支持问题。
至于DISKSTORE方式,是从Redis Version 2.8版本开始提出的一个存储设想,到目前为止Redis官方也没有在任何stable版本中明确建议使用这用方式。在Version 3.2版本中同样找不到对于这种存储方式的明确支持。从网络上能够收集到的各种资料来看,DISKSTORE方式和RDB方式还有着一些千丝万缕的联系。
最关键的是目前官方文档上能够看到的Redis对持久化存储的支持明确的就只有两种方案(https://redis.io/topics/persistence):RDB和AOF。
RDB持久化
RDB快照用官方的话来说:RDB持久化方案是按照指定时间间隔对你的数据集生成的时间点快照(point-to-time snapshot)。它以紧缩的二进制文件保存Redis数据库某一时刻所有数据对象的内存快照,可用于Redis的数据备份、转移与恢复。
工作原理
既然说RDB是Redis中数据集的时间点快照,先简单了解一下Redis内的数据对象在内存中是如何存储与组织的。
默认情况下,Redis中有16个数据库,编号从0-15,每个Redis数据库使用一个redisDb对象来表示,redisDb使用hashtable存储K-V对象。为方便理解,我以其中一个db为例绘制Redis内部数据的存储结构示意图。
时间点快照也就是某一时刻Redis内每个DB中每个数据对象的状态,先假设在这一时刻所有的数据对象不再改变,我们就可以按照上图中的数据结构关系,把这些数据对象依次读取出来并写入到文件中,以此实现Redis的持久化。然后,当Redis重启时按照规则读取这个文件中的内容,再写入到Redis内存即可恢复至持久化时的状态。
当然,这个前提时我们上面的假设成立,否则面对一个时刻变化的数据集,我们无从下手。我们知道Redis中客户端命令处理是单线程模型,如果把持久化作为一个命令处理,那数据集肯定时处于静止状态。另外,操作系统提供的fork()函数创建的子进程可获得与父进程一致的内存数据,相当于获取了内存数据副本;fork完成后,父进程该干嘛干嘛,持久化状态的工作交给子进程就行了。
很显然,第一种情况不可取,持久化备份会导致短时间内Redis服务不可用,这对于高HA的系统来讲是无法容忍的。所以,第二种方式是RDB持久化的主要实践方式。由于fork子进程后,父进程数据一直在变化,子进程并不与父进程同步,RDB持久化必然无法保证实时性;RDB持久化完成后发生断电或宕机,会导致部分数据丢失;备份频率决定了丢失数据量的大小,提高备份频率,意味着fork过程消耗较多的CPU资源,也会导致较大的磁盘I/O。
AOF持久化
AOF (Append Only File) 持久化:Redis先执行命令,把数据写入内存,然后才记录日志。AOF 是将 Redis 每次写入操作记录下来的过程。AOF 文件是一个文本文件,每次写入操作都会追加到文件末尾。
适用于数据量较大的场景,因为 AOF 文件可以实时保存数据变更,并且可以通过重放 AOF 文件中的写入操作来恢复数据。
BTW: 大多数的数据库采用的是写前日志(WAL),例如MySQL,通过写前日志和两阶段提交,实现数据和逻辑的一致性。
AOF重写过程是由后台进程bgrewriteaof来完成的。主线程fork出后台的bgrewriteaof子进程,fork会把主线程的内存拷贝一份给bgrewriteaof子进程,这里面就包含了数据库的最新数据。然后,bgrewriteaof子进程就可以在不影响主线程的情况下,逐一把拷贝的数据写成操作,记入重写日志。
所以aof在重写时,在fork进程时是会阻塞住主线程的。
重写日志时,有新数据写入怎么办?
重写过程总结为:“一个拷贝,两处日志”。在fork出子进程时的拷贝,以及在重写时,如果有新数据写入,主线程就会将命令记录到两个aof日志内存缓冲区中。如果AOF写回策略配置的是always,则直接将命令写回旧的日志文件,并且保存一份命令至AOF重写缓冲区,这些操作对新的日志文件是不存在影响的。(旧的日志文件:主线程使用的日志文件,新的日志文件:bgrewriteaof进程使用的日志文件)
而在bgrewriteaof子进程完成会日志文件的重写操作后,会提示主线程已经完成重写操作,主线程会将AOF重写缓冲中的命令追加到新的日志文件后面。这时候在高并发的情况下,AOF重写缓冲区积累可能会很大,这样就会造成阻塞,Redis后来通过Linux管道技术让aof重写期间就能同时进行回放,这样aof重写结束后只需回放少量剩余的数据即可。
最后通过修改文件名的方式,保证文件切换的原子性。
在AOF重写日志期间发生宕机的话,因为日志文件还没切换,所以恢复数据时,用的还是旧的日志文件。
总结操作:
- 主线程fork出子进程重写aof日志
- 子进程重写日志完成后,主线程追加aof日志缓冲
- 替换日志文件
Q&A
Redis线程线程安全吗?
Redis中本身就是单线程的能够保证线程安全问题。
Redis实际上是采用了线程封闭的观念,把任务封闭在一个线程,自然避免了线程安全问题,不过对于需要依赖多个redis操作的复合操作来说,依然需要锁,而且有可能是分布式锁。
多线程模式下,是否存在线程并发安全问题?
在redis的多线程模式下,获取、解析命令,以及输出结果着两个过程,可以配置成多线程执行的,因为它毕竟是我们定位到的主要耗时点,但是命令的执行,也就是内存操作,依然是单线程运行的。所以,Redis 的多线程部分只是用来处理网络数据的读写和协议解析,执行命令仍然是单线程顺序执行,也就不存在并发安全问题。
Redis线程为什么效率这么高?为什么快?
- 完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1);
- 数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的;
- 采用单线程,避免了不必要的上下文切换和竞争条件。也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
- 使用多路I/O复用模型,非阻塞IO;
IO多路复用中有三种方式:select,poll,epoll。需要注意的是,select,poll是线程不安全的,epoll是线程安全的。NIO模式的IO多路复用底层原理 - 使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
穿透、雪崩、击穿
用户的数据一般都是存储于数据库,数据库的数据是落在磁盘上的,磁盘的读写速度可以说是计算机里最慢的硬件了。
当用户的请求,都访问数据库的话,请求数量一上来,数据库很容易就奔溃的了,所以为了避免用户直接访问数据库,会用 Redis 作为缓存层。
因为 Redis 是内存数据库,我们可以将数据库的数据缓存在 Redis 里,相当于数据缓存在内存,内存的读写速度比硬盘快好几个数量级,这样大大提高了系统性能。
引入了缓存层,就会有缓存异常的三个问题,分别是缓存雪崩、缓存击穿、缓存穿透。
这三个问题也是面试中很常考察的问题,我们不光要清楚地知道它们是怎么发生,还需要知道如何解决它们。
缓存雪崩
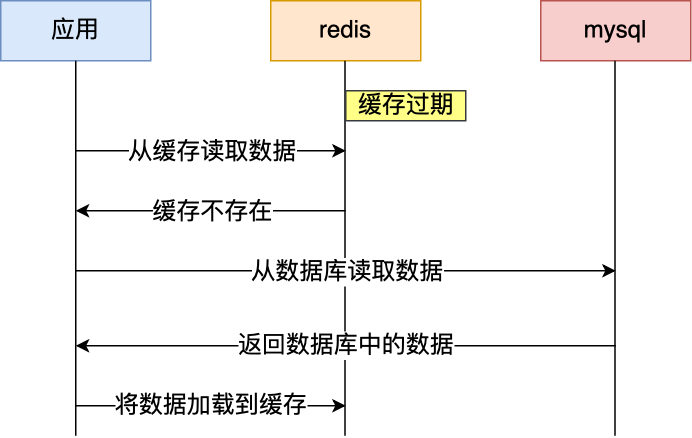
通常我们为了保证缓存中的数据与数据库中的数据一致性,会给 Redis 里的数据设置过期时间,当缓存数据过期后,用户访问的数据如果不在缓存里,业务系统需要重新生成缓存,因此就会访问数据库,并将数据更新到 Redis 里,这样后续请求都可以直接命中缓存
那么,当大量缓存数据在同一时间过期(失效)或者 Redis 故障宕机时,如果此时有大量的用户请求,都无法在 Redis 中处理,于是全部请求都直接访问数据库,从而导致数据库的压力骤增,严重的会造成数据库宕机,从而形成一系列连锁反应,造成整个系统崩溃,这就是缓存雪崩的问题。
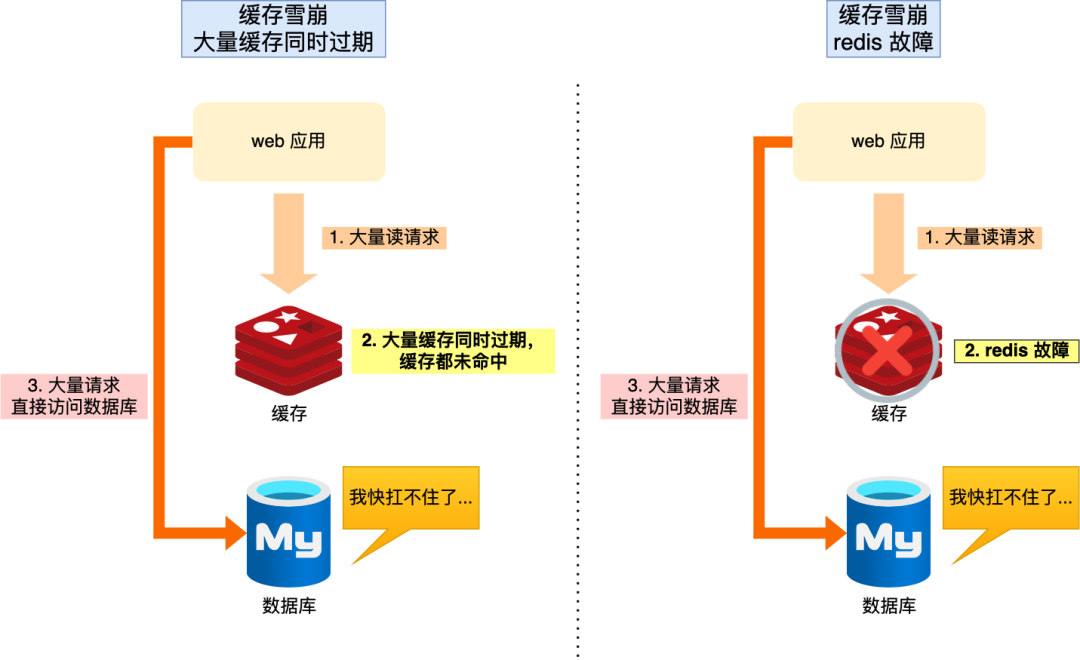
可以看到,发生缓存雪崩有两个原因:
- 大量数据同时过期;
- Redis 故障宕机;
不同的诱因,应对的策略也会不同。
大量数据同时过期
针对大量数据同时过期而引发的缓存雪崩问题,常见的应对方法有下面这几种:
- 均匀设置过期时间;
- 互斥锁;
- 双 key 策略;
- 后台更新缓存;
1. 均匀设置过期时间
如果要给缓存数据设置过期时间,应该避免将大量的数据设置成同一个过期时间。我们可以在对缓存数据设置过期时间时,给这些数据的过期时间加上一个随机数,这样就保证数据不会在同一时间过期。
2. 互斥锁
当业务线程在处理用户请求时,如果发现访问的数据不在 Redis 里,就加个互斥锁,保证同一时间内只有一个请求来构建缓存(从数据库读取数据,再将数据更新到 Redis 里),当缓存构建完成后,再释放锁。未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么就返回空值或者默认值。
实现互斥锁的时候,最好设置超时时间,不然第一个请求拿到了锁,然后这个请求发生了某种意外而一直阻塞,一直不释放锁,这时其他请求也一直拿不到锁,整个系统就会出现无响应的现象。
3. 双 key 策略
我们对缓存数据可以使用两个 key,一个是主 key,会设置过期时间,一个是备 key,不会设置过期,它们只是 key 不一样,但是 value 值是一样的,相当于给缓存数据做了个副本。
当业务线程访问不到「主 key 」的缓存数据时,就直接返回「备 key 」的缓存数据,然后在更新缓存的时候,同时更新「主 key 」和「备 key 」的数据。
双 key 策略的好处是,当主 key 过期了,有大量请求获取缓存数据的时候,直接返回备 key 的数据,这样可以快速响应请求。而不用因为 key 失效而导致大量请求被锁阻塞住(采用了互斥锁,仅一个请求来构建缓存),后续再通知后台线程,重新构建主 key 的数据。
4. 后台更新缓存
业务线程不再负责更新缓存,缓存也不设置有效期,而是让缓存“永久有效”,并将更新缓存的工作交由后台线程定时更新。
事实上,缓存数据不设置有效期,并不是意味着数据一直能在内存里,因为当系统内存紧张的时候,有些缓存数据会被“淘汰”,而在缓存被“淘汰”到下一次后台定时更新缓存的这段时间内,业务线程读取缓存失败就返回空值,业务的视角就以为是数据丢失了。
解决上面的问题的方式有两种。
第一种方式,后台线程不仅负责定时更新缓存,而且也负责频繁地检测缓存是否有效,检测到缓存失效了,原因可能是系统紧张而被淘汰的,于是就要马上从数据库读取数据,并更新到缓存。
这种方式的检测时间间隔不能太长,太长也导致用户获取的数据是一个空值而不是真正的数据,所以检测的间隔最好是毫秒级的,但是总归是有个间隔时间,用户体验一般。
第二种方式,在业务线程发现缓存数据失效后(缓存数据被淘汰),通过消息队列发送一条消息通知后台线程更新缓存,后台线程收到消息后,在更新缓存前可以判断缓存是否存在,存在就不执行更新缓存操作;不存在就读取数据库数据,并将数据加载到缓存。这种方式相比第一种方式缓存的更新会更及时,用户体验也比较好。
在业务刚上线的时候,我们最好提前把数据缓起来,而不是等待用户访问才来触发缓存构建,这就是所谓的缓存预热,后台更新缓存的机制刚好也适合干这个事情。
Redis 故障宕机
- 服务熔断或请求限流机制;
- 构建 Redis 缓存高可靠集群;
1. 服务熔断或请求限流机制
因为 Redis 故障宕机而导致缓存雪崩问题时,我们可以启动服务熔断机制,暂停业务应用对缓存服务的访问,直接返回错误,不用再继续访问数据库,从而降低对数据库的访问压力,保证数据库系统的正常运行,然后等到 Redis 恢复正常后,再允许业务应用访问缓存服务。
服务熔断机制是保护数据库的正常允许,但是暂停了业务应用访问缓存服系统,全部业务都无法正常工作
为了减少对业务的影响,我们可以启用请求限流机制,只将少部分请求发送到数据库进行处理,再多的请求就在入口直接拒绝服务,等到 Redis 恢复正常并把缓存预热完后,再解除请求限流的机制。
2. 构建 Redis 缓存高可靠集群
服务熔断或请求限流机制是缓存雪崩发生后的应对方案,我们最好通过主从节点的方式构建 Redis 缓存高可靠集群。
如果 Redis 缓存的主节点故障宕机,从节点可以切换成为主节点,继续提供缓存服务,避免了由于 Redis 故障宕机而导致的缓存雪崩问题。
缓存击穿
我们的业务通常会有几个数据会被频繁地访问,比如秒杀活动,这类被频地访问的数据被称为热点数据。
如果缓存中的某个热点数据过期了,此时大量的请求访问了该热点数据,就无法从缓存中读取,直接访问数据库,数据库很容易就被高并发的请求冲垮,这就是缓存击穿的问题。
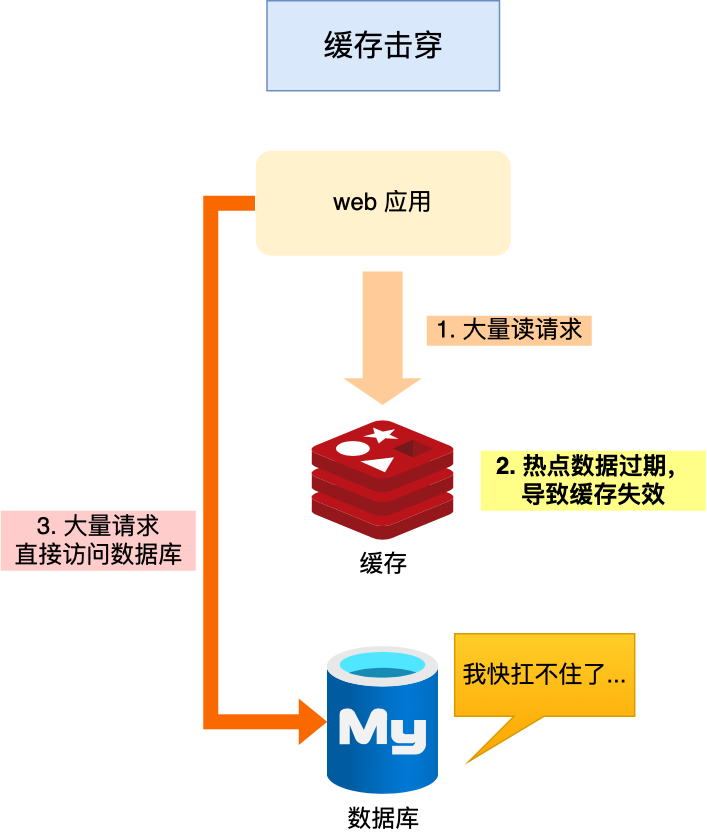
可以发现缓存击穿跟缓存雪崩很相似,你可以认为缓存击穿是缓存雪崩的一个子集。
应对缓存击穿可以采取前面说到两种方案:
- 互斥锁方案,保证同一时间只有一个业务线程更新缓存,未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么就返回空值或者默认值。
- 不给热点数据设置过期时间,由后台异步更新缓存,或者在热点数据准备要过期前,提前通知后台线程更新缓存以及重新设置过期时间;
缓存穿透
当发生缓存雪崩或击穿时,数据库中还是保存了应用要访问的数据,一旦缓存恢复相对应的数据,就可以减轻数据库的压力,而缓存穿透就不一样了。
当用户访问的数据,既不在缓存中,也不在数据库中,导致请求在访问缓存时,发现缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据,没办法构建缓存数据,来服务后续的请求。那么当有大量这样的请求到来时,数据库的压力骤增,这就是缓存穿透的问题。
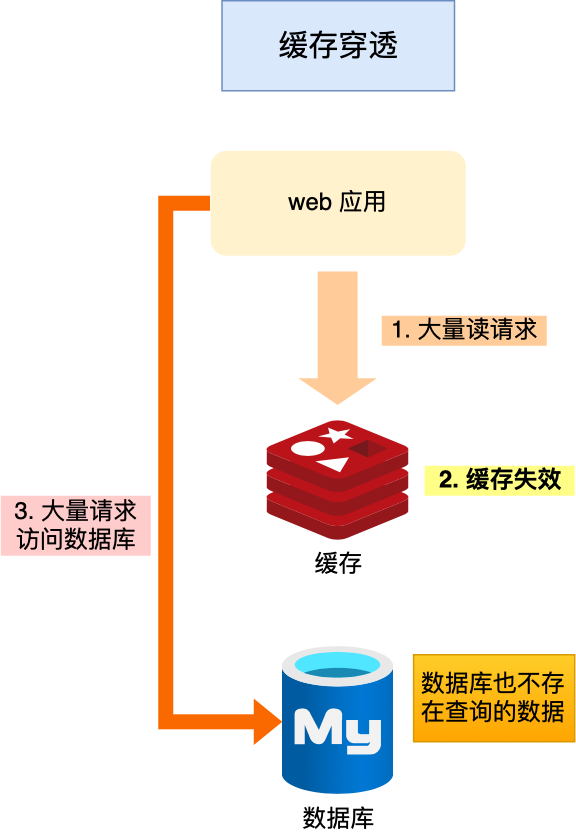
缓存穿透的发生一般有这两种情况:
- 业务误操作,缓存中的数据和数据库中的数据都被误删除了,所以导致缓存和数据库中都没有数据;
- 黑客恶意攻击,故意大量访问某些读取不存在数据的业务;
应对缓存穿透的方案,常见的方案有三种。
- 第一种方案,非法请求的限制;
- 第二种方案,缓存空值或者默认值;
- 第三种方案,使用布隆过滤器快速判断数据是否存在,避免通过查询数据库来判断数据是否存在;
第一种方案,非法请求的限制
当有大量恶意请求访问不存在的数据的时候,也会发生缓存穿透,因此在 API 入口处我们要判断求请求参数是否合理,请求参数是否含有非法值、请求字段是否存在,如果判断出是恶意请求就直接返回错误,避免进一步访问缓存和数据库。
第二种方案,缓存空值或者默认值
当我们线上业务发现缓存穿透的现象时,可以针对查询的数据,在缓存中设置一个空值或者默认值,这样后续请求就可以从缓存中读取到空值或者默认值,返回给应用,而不会继续查询数据库。
第三种方案,使用布隆过滤器快速判断数据是否存在,避免通过查询数据库来判断数据是否存在。
我们可以在写入数据库数据时,使用布隆过滤器做个标记,然后在用户请求到来时,业务线程确认缓存失效后,可以通过查询布隆过滤器快速判断数据是否存在,如果不存在,就不用通过查询数据库来判断数据是否存在。
即使发生了缓存穿透,大量请求只会查询 Redis 和布隆过滤器,而不会查询数据库,保证了数据库能正常运行,Redis 自身也是支持布隆过滤器的。
那问题来了,布隆过滤器是如何工作的呢?接下来,我介绍下。
布隆过滤器由「初始值都为 0 的位图数组」和「 N 个哈希函数」两部分组成。当我们在写入数据库数据时,在布隆过滤器里做个标记,这样下次查询数据是否在数据库时,只需要查询布隆过滤器,如果查询到数据没有被标记,说明不在数据库中。
布隆过滤器会通过 3 个操作完成标记:
- 第一步,使用 N 个哈希函数分别对数据做哈希计算,得到 N 个哈希值;
- 第二步,将第一步得到的 N 个哈希值对位图数组的长度取模,得到每个哈希值在位图数组的对应位置。
- 第三步,将每个哈希值在位图数组的对应位置的值设置为 1;
举个例子,假设有一个位图数组长度为 8,哈希函数 3 个的布隆过滤器。
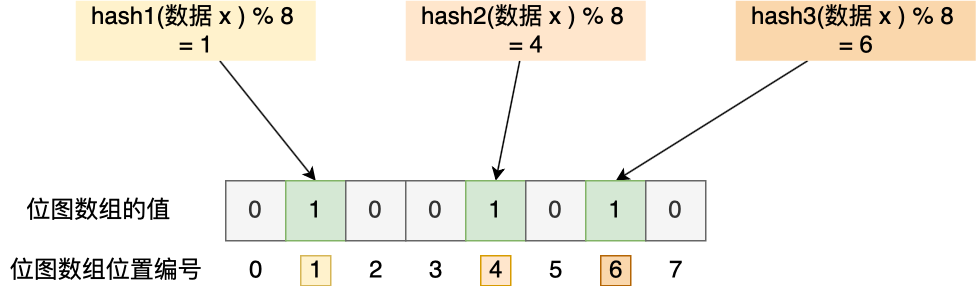
在数据库写入数据 x 后,把数据 x 标记在布隆过滤器时,数据 x 会被 3 个哈希函数分别计算出 3 个哈希值,然后在对这 3 个哈希值对 8 取模,假设取模的结果为 1、4、6,然后把位图数组的第 1、4、6 位置的值设置为 1。当应用要查询数据 x 是否数据库时,通过布隆过滤器只要查到位图数组的第 1、4、6 位置的值是否全为 1,只要有一个为 0,就认为数据 x 不在数据库中。
布隆过滤器由于是基于哈希函数实现查找的,高效查找的同时存在哈希冲突的可能性,比如数据 x 和数据 y 可能都落在第 1、4、6 位置,而事实上,可能数据库中并不存在数据 y,存在误判的情况。
所以,查询布隆过滤器说数据存在,并不一定证明数据库中存在这个数据,但是查询到数据不存在,数据库中一定就不存在这个数据。
总结
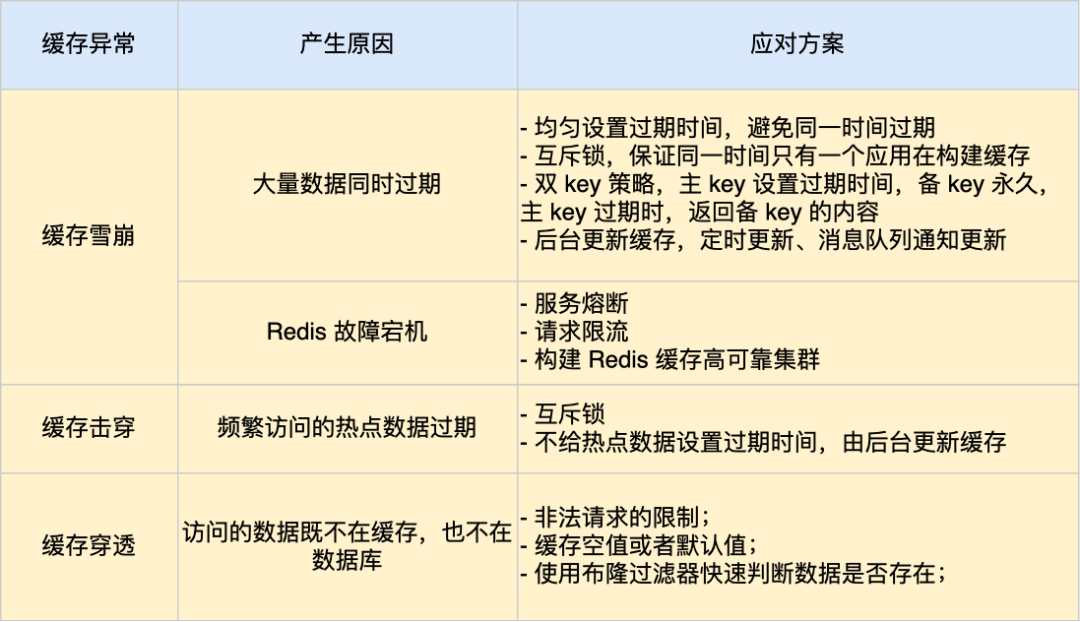
缓存异常会面临的三个问题:缓存雪崩、击穿和穿透。
其中,缓存雪崩和缓存击穿主要原因是数据不在缓存中,而导致大量请求访问了数据库,数据库压力骤增,容易引发一系列连锁反应,导致系统奔溃。不过,一旦数据被重新加载回缓存,应用又可以从缓存快速读取数据,不再继续访问数据库,数据库的压力也会瞬间降下来。因此,缓存雪崩和缓存击穿应对的方案比较类似。
而缓存穿透主要原因是数据既不在缓存也不在数据库中。因此,缓存穿透与缓存雪崩、击穿应对的方案不太一样。
我这里整理了表格,你可以从下面这张表格很好的知道缓存雪崩、击穿和穿透的区别以及应对方案。
References
http://www.w3cschool.cn/redis/redis-intro.html
https://jiajunhuang.com/articles/2021_06_06-redis_source_code_11.md.html